Настройка Tantor Postgres для работы 1С
ver. 1.8 from 22.10.25
Установка настроек по умолчанию для 1С.
1. Заходим в платформу Tantor, выбираем наш инстанс, где расположены базы 1С.
2. Слева в меню выбираем пункт «monitoring config»:

3. В списке баз выделяем базу 1С, нажимаем на «Save»:
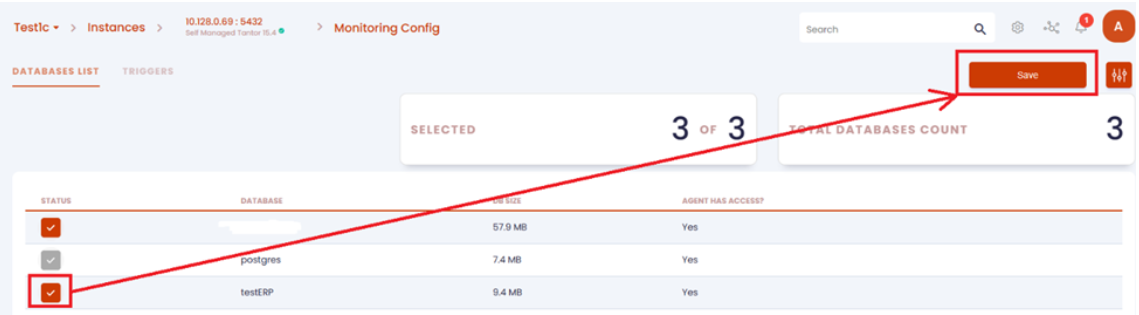
4. После этого агент идет в БД и пытается найти специфичные таблицы под 1С, и если находит, то шлет в платформу сообщение, что это 1С. Конфигурация настроек под 1с автоматически загрузится в тантор в качестве рекомендуемых.
5. Через несколько минут заходим на вкладку «Configurations» и проверяем, что выбранный профиль равен erp1c:
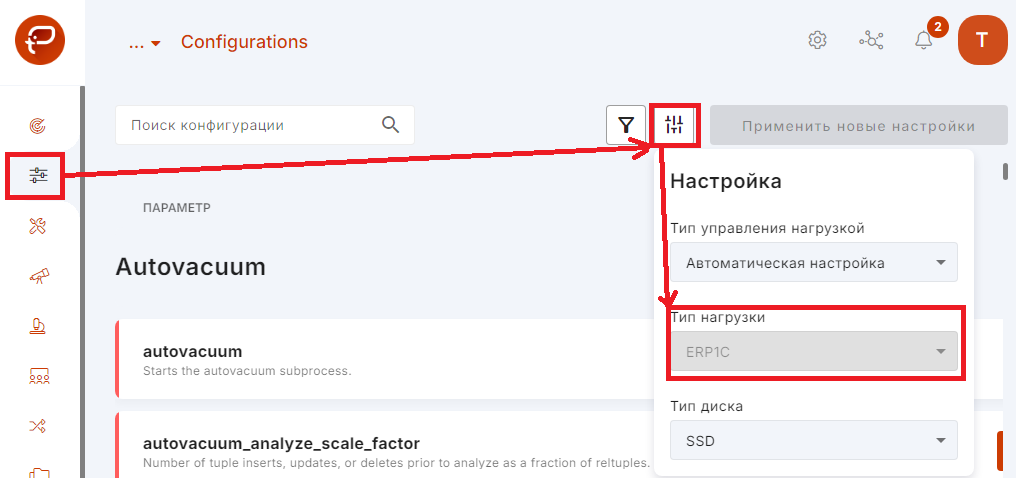
6. Теперь в колонке «CHANGE CURRENT VALUE TO RECOMMENDED» платформа предоставляет те значения, которые она рекомендует для профиля erp1c. Применять или не применять рекомендуемые значения вы должны определить сами. Ниже мы опишем основные настройки, которые влияют на работу 1С.
Также есть аналогичная видеоинструкция - Rutube/Youtube
Параметры Tantor
Дополнительные модули (расширения)
При создании базы платформа 1С автоматически подключит к базе следующие расширения, необходимые для совместимости с 1С:
Делает это платформа следующими запросами согласно логов технологического журнала 1С:
37:16.686000-1999,DBPOSTGRS,3,Sql="select installed_version from pg_available_extensions where name = 'mchar'"
37:16.686002-1,DBPOSTGRS,3,Sql=alter extension mchar update
37:16.687000-997,DBPOSTGRS,3,Sql="select installed_version from pg_available_extensions where name = 'fasttrun'"
37:16.688000-999,DBPOSTGRS,3,Sql=alter extension fasttrun update
37:16.689000-999,DBPOSTGRS,3,Sql="select installed_version from pg_available_extensions where name = 'fulleq'"
37:16.689002-1,DBPOSTGRS,3,Sql=alter extension fulleq updateПосмотреть установленные расширения можно следующим запросом:
SELECT * FROM pg_extensionСоединения и аутентификация (Connections and Authentication)
| Имя параметра | Рекомендуемое значение | Описание |
|---|---|---|
| listen_addresses | * | Задаёт адреса TCP/IP, по которым сервер будет принимать подключения клиентских приложений. |
| port | 5432 | TCP-порт, открываемый сервером; по умолчанию, 5432. Заметьте, что этот порт используется для всех IP-адресов, через которые сервер принимает подключения. Этот параметр можно задать только при запуске сервера. |
| ssl | off | Выключение шифрования, которое может приводить к увеличению загрузки CPU. В 1С не используется. |
| max_connections | 1000 | Определяет максимальное число одновременных подключений к серверу БД. Данный параметр нужно рассчитывать исходя из того сколько пользователей всех баз 1С могут одновременно подключиться к настраиваемому серверу СУБД. Стоит учесть, что в это число также входит количество «слотов» подключений, которые Tantor Postgres будет резервировать для суперпользователей - регулируется параметром superuser_reserved_connections. Когда число активных одновременных подключений больше или равно max_connections минус superuser_reserved_connections, принимаются только подключения суперпользователей, а все другие подключения, в том числе подключения для репликации, запрещаются. |
Настройки WAL (Write-Ahead Log)
Для высоконагруженных систем рекомендуем выносить журнал транзакций на отдельный диск. Это может даст прирост производительности особенно для oltp характера нагрузки.
| Имя параметра | Рекомендуемое значение | Описание |
|---|---|---|
| fsync | on | Данный параметр отвечает за сброс данных из кэша на диск при завершении транзакций. Если установить его значение fsync=off то данные не будут записываться на дисковые накопители сразу после завершения операций. Это может существенно повысить скорость операций insert и update, но есть риск повредить базу, если произойдет сбой (неожиданное отключение питания, сбой ОС, сбой дисковой подсистемы). Повышение производительности возможно при использовании многодисковых RAID-массивов, созданных на основе кэширующих RAID-контроллеров с энергонезависимой кэш-памятью и использования источников бесперебойного питания(UPS). В этом случае задачу по обеспечению консистентности данных при аппаратном сбое берут на себя описанные выше устройства, поэтому появляется возможность отключения параметра fsync и увеличения производительности операций записи на диск. Следует отметить, что увеличение количества дисков в RAID-массиве и объема кеша RAID-контроллера само по себе позволяет компенсировать снижение производительности, обусловленное включением параметра fsync. |
| full_page_writes | on | Включение этого параметра гарантирует корректное восстановление, ценой увелечения записываемых данных в журнал транзакций. Отключение этого параметра ускоряет работу, но может привести к повреждению базы данных в случае системного сбоя или отключения питания. Так как при этом возникают практически те же риски, что и при отключении fsync, хотя и в меньшей степени, отключать его следует только при тех же обстоятельствах, которые перечислялись в рекомендациях для вышеописанного параметра. |
| synchronous_commit | off | Выключение синхронной записи в WAL момент коммита транзакции. Создает риск потери последних нескольких транзакций (в течении 0.5-1" секунды), но гарантирует целостность базы данных. Может значительно увеличить производительность. При выключении обязательно наличие ИБП на сервере СУБД и системы мониторинга, которая сообщит об аварии электропитания и корректно выключит сервер СУБД |
| wal_level | replica | В продуктиве наличие реплики обязательно! |
| max_wal_senders | 2 | Равен количеству реплик + 1 |
| min_wal_size | 4GB | Этот параметр ограничивает размер WAL снизу. Этим самым мы резервируем некоторое место для WAL, чтобы справиться с резкими скачками его использования. |
| max_wal_size | min_wal_size*2 | Максимальный размер, до которого может вырастать WAL. Если мы приближаемся к этому порогу, то будет выполнена дополнительная контрольная точка и старые (не нужные) записи из WAL будут удалены. Размер WAL может превышать max_wal_size при особых обстоятельствах, например при большой нагрузке. Уменьшение этого параметра сделает более частыми контрольные точки, при этом возрастёт нагрузка. Но зато восстановления баз данных в случае сбоя будет происходить быстрее. Увеличение этого параметра может привести к увеличению времени, которое потребуется для восстановления после сбоя. |
| wal_keep_size | max_wal_size*0.9 | Задаёт минимальный объём прошлых сегментов журнала WAL, который будет сохраняться, чтобы ведомый сервер мог выбрать их при потоковой репликации. Если ведомый сервер, подключённый к передающему, отстаёт больше чем на wal_keep_size, то репликация может сломаться. Если у вас используется репликация на ведомый сервер, то задайте этот параметр немного меньше чем max_wal_size. |
| checkpoint_timeout | 15min | Максимальное время между автоматическими контрольными точками в WAL. Увеличение этого параметра может привести к увеличению времени, которое потребуется для восстановления после сбоя. |
| checkpoint_warning | 3min | Если контрольные точки будут случаться чаще 3 минут, то вы увидите записи об этом в журнале с рекомендацией увеличить max_wal_size |
| checkpoint_completion_target | 0.9 | Этот параметр задает долю от общего времени между контрольными точками. Например, контрольные точки происходят раз в 15 минут. А для параметра checkpoint_completion_target мы установим значение 0,9. Это будет означать что контрольные точки будут происходить раз в 15 минут, а сам процесс сброса данных на диск будет происходить 15*0,9 = 13,5 минуты. Остальные 1,5 минуты останутся для запаса, например для завершения контрольной точки. Значение этого параметра не рекомендуется изменять. Если задать его слишком маленьким, то в момент контрольной точки будет слишком сильная нагрузка на диск. А если указать 1, то контрольные точки не будут успевать завершаться. А значение 0,9 позволяет сделать нагрузку на диск более плавной и оставляет некоторое время на завершение контрольной точки. |
| commit_delay | 1000 | Групповой коммит нескольких транзакций. Имеет смысл включать, если интенсивность транзакций превосходит 1000 TPS. Если при успешном завершении транзакции активно не менее commit_siblings транзакций, то запись будет задержана на время commit_delay. Не работает при выключенном fsync. |
| commit_siblings | 5 | Устанавливает минимальное количество одновременных открытых транзакций перед выполнением commit_delay |
Использование ресурсов (Resource usage)
| Имя параметра | Рекомендуемое значение | Описание |
|---|---|---|
| shared_buffers | RAM/4 | Этот параметр устанавливает, сколько выделенной памяти будет использоваться Tantor Postgres для кеширования. Эта память разделяется между всеми процессами Tantor Postgres. |
| temp_buffers | 256MB | Задаёт максимальный объём памяти, выделяемой для временных таблиц в каждом сеансе. |
| work_mem | 256MB | Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребляемая память равна max_connections * work_mem, но на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании. Это рекомендательное значение используется планировщиком: он пытается предугадать размер необходимой памяти для запроса, и, если это значение больше work_mem, то указывает исполнителю сразу создать временную таблицу. work_mem не является в полном смысле лимитом: планировщик может и промахнуться, и запрос займёт больше памяти, возможно в разы. Данный параметр должен корректироваться статистически, в зависимости от того использует ли сервер СУБД в работе временные файлы (кроме загрузки dt). Узнать сколько и какого объёма были созданы временные файлы можно запросом: select sum(temp_files) as temp_files, pg_size_pretty(sum(temp_bytes)) as temp_size from pg_stat_database; |
| hash_mem_multiplier | 8 | Этот параметр определяет множитель для расчета максимального объема памяти, используемой при выполнении хеш-операций. Умножается на значение work_mem для операций хеширования, таких как построение хеш-таблиц в hash join и агрегатных операциях. Позволяет выделять больше памяти для хеш-операций без увеличения work_mem для других типов операций. |
| maintenance_work_mem | work_mem*4 | Лимит памяти для обслуживающих задач, например AutoVacuum, Vacuum или CREATE INDEX. |
| effective_cache_size | RAM*0.75 (RAM - shared_buffers) | Tantor Postgres в своих планах опирается на кэширование файлов, осуществляемое операционной системой. Этот параметр соответствует максимальному размеру объекта, который может поместиться в системный кэш. Это значение используется только для оценки. |
| hash_mem_multiplier | 8 | |
| max_files_per_process | 10000 | В конфигурации 1С десятки тысяч таблиц и индексов и при этом каждая таблица/индекс может состоять из нескольких файлов. В итоге Tantor Postgres “достигнув” лимита открытых файлов начинает их закрывать/открывать, что может негативно сказаться на производительности. |
| max_parallel_workers_per_gather | 0 | Если вы понимаете, что в вашей базе основное это OLTP нагрузка, то лучше отключить параллелизм, поставив 0. Иначе можно эксперементировать с ним, поставив 2 и посмотреть как изменится APDEX системы в целом |
| max_parallel_workers | 8 | Если вы используете параллелизм, то следует указать сколько ядер одновременно он может использовать. Например, значение этого параметра 8, а max_parallel_workers_per_gather = 2 - значит 4 запроса одновременно смогут распараллелится. |
| max_worker_processes | CPU | Максимальное число фоновых процессов. В данный параметр нужно выставлять количество ядер, выделенных для Tantor Postgres. |
| max_parallel_maintenance_workers | CPU/2 | Задаёт максимальное число параллельных процессов на одну операцию обслуживания. Для 1С актуально для операции CREATE INDEX, т.е. в моменты реструктуризации базы и создании базы загрузкой из DT. |
| bgwriter_delay | 20 | В Tantor Postgres есть специальный процесс фоновой записи. Этот процесс отвечает за сброс грязных буферов из shared_buffer на диск. Когда количество shared_buffer уже недостаточно, данный процесс записывает изменённые страницы на диск, освобождая память. Это снижает вероятность того, что процессы, выполняющие запросы пользователей, не смогут найти чистые буферы и им придётся сбрасывать грязные буферы самостоятельно. Но процесс фоновой записи увеличивает общую нагрузку на диск, так как он может записывать неоднократно изменяемую страницу несколько раз, тогда как её можно было бы записать всего один раз (при checkpoint). Этот параметр задаёт задержку между раундами активности фоновой записи. Во время раунда этот процесс осуществляет запись некоторого количества грязных буферов на диск. Затем он засыпает на время bgwriter_delay, и всё повторяется снова. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс. А слишком маленькое значение будет грузить процессор, так как постоянно будет запускаться процесс фоновой записи. |
| bgwriter_lru_maxpages | 400 | Максимальное число буферов, которое сможет записать процесс фоновой записи за раунд. При нулевом значении фоновая запись отключается. |
| bgwriter_lru_multiplier | 4 | Число записываемых грязных буферов на диск данных процессом фоновой записи может быть больше чем в предыдущий раз в указанное количество раз. Другими словами, bgwriter_lru_multiplier это множитель. Средняя недавняя потребность умножается на bgwriter_lru_multiplier и предполагается что именно столько данных потребуется записать. Увеличение этого множителя больше 1 даёт некоторую страховку от резких скачков потребностей. |
| effective_io_concurrency | 128 | Параметр задаёт допустимое число параллельных операций ввода/вывода. Чем больше это число, тем больше операций ввода/вывода будет пытаться выполнить параллельно Tantor Postgres в отдельном сеансе. Для жестких дисков указывается по количеству шпинделей, для массивов RAID5/6 следует исключить диски четности. Для SATA SSD это значение рекомендуется указывать равным 128, а для быстрых NVMe дисков его можно увеличить до 500-1000. При этом следует понимать, что высокие значения в сочетании с медленными дисками сделают обратный эффект, поэтому подходите к этой настройке грамотно. |
| maintenance_io_concurrency | 128 | Вариация параметра effective_io_concurrency, предназначенная для операций обслуживания БД. |
| huge_pages | try | Включает использование огромных страниц. Имеет смысл использовать, если количество ОЗУ 32 Гб и более, иначе можно установить в off. Страница — это часть оперативной памяти, выделенная процессу. Процесс может иметь несколько страниц в зависимости от требований к памяти. Чем больше памяти требуется процессу, тем больше страниц ему выделено. ОС поддерживает таблицу выделения страниц для процессов. Чем меньше размер страницы, тем больше таблица, тем больше времени требуется для поиска страницы в этой таблице страниц. Поэтому большие страницы позволяют использовать большой объем памяти с уменьшенными накладными расходами; меньше просмотров страниц, меньше ошибок страниц, более быстрые операции чтения/записи через большие буферы. Как результат — улучшение производительности. Как правильно настроить huge pages читайте в разделе "Настройка sysctl.conf". |
| enable_delayed_temp_file | on | Включает размещение в оперативной памяти всех файлов, которые создаются при использовании временных таблиц. Позволяет значительно снизить нагрузку на дисковую систему. |
| enable_temp_memory_catalog | on | Включение данного параметра приводит к тому, что все метаданные, используемые для работы временных таблиц, хранятся в оперативной памяти сеанса, а не в системном каталоге Tantor Postgres. Это позволяет убрать раздутие таблиц системного каталога (pg_class, pg_attribute, pg_type и тд) и экономить ресурсы процесса Autovacuum, благодаря чему пользовательские таблицы будут оперативнее обслуживаться. |
| enable_pgstat_for_temp_rel | off | Отключение данного параметра отключает сбор статистики по временным таблицам в общую хэш-таблицу Tantor Postgres. Это решает проблему блокировок LWLock и деградации производительности при частых операциях с временными таблицами, статистика по которым не критична для работы системы. |
Настройка запросов (Query Tuning)
| Имя параметра | Рекомендуемое значение | Описание |
| default_statistics_target | 100 | Количество записей, просматриваемых при сборе статистики по таблицам при выполнении команды ANALYZE. Чем больше установленное значение, тем больше времени требуется для выполнения ANALYZE, но тем выше может быть качество оценок планировщика. Для 1С большое значение может быть критично, т.к. команда ANALYZE выполняется при каждом создании временной таблицы. Рекомендуем оставлять этот параметр равным 100. Более подробно о влиянии данной настройки на время выполнения команды ANALYZE можно почитать здесь. |
| default_statistics_target_temp_tables | 100 | Данный параметр аналогичен параметру default_statistics_target, только он управляет точностью статистики временных таблиц, что в сочетании с default_statistics_target обеспечивает независимую настройку детализации статистики для постоянных и временных таблиц. |
| cpu_operator_cost | 0.001 | Задаёт приблизительную стоимость обработки оператора или функции при выполнении запроса. Платформа 1с при выполнении каждого запроса явно ставит значение 0.001, поэтому повлиять на стоимость этого оператора возможности нет. |
| seq_page_cost | 1 | Задаёт приблизительную стоимость чтения одной страницы с диска, которое выполняется в серии последовательных чтений. Этот параметр является шкалой для всех остальных параметров секции #Planner Cost Constants#, поэтому его менять крайне не рекомендуется. Для производительных NVMe-дисков можно изменить параметр на 0.1 вместе с параметром random_page_cost. |
| random_page_cost | 1.1 | Стоимость чтения рандомной страницы, на которую будет опираться оптимизатор. Практическое значение параметра должно зависеть от «seek time» дисковой системы: чем он меньше, тем меньше должно быть значение random_page_cost. Излишне большое значение параметра увеличивает склонность Tantor Postgres к выбору планов с сканированием всей таблицы (Tantor Postgres считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). Оценка стоимости последовательного чтения делается, в свою очередь, с учетом параметра seq_page_cost, который равен по умолчанию 1. Рекомендации: 4.0 — для HDD; |
| from_collapse_limit | 20 | Задаёт максимальное число элементов в списке FROM, до которого планировщик будет объединять вложенные запросы с внешним запросом. При больших значениях увеличивается время планирования, но план запроса может стать более эффективным. |
| join_collapse_limit | 20 | Задаёт максимальное количество элементов в списке FROM, до достижения которого планировщик будет сносить в него явные конструкции JOIN (за исключением FULL JOIN). При больших значениях увеличивается время планирования, но план запроса может стать более эффективным. |
| geqo | on | GEQO - генетический оптимизатор запросов PоstgreSQL, который осуществляет планирование запросов, применяя эвристический поиск вместо полного перебора отношений. Он позволяет сократить время планирования для сложных запросов с большим числом соединений, потому не рекомендуется его отключать. Однако надо учитывать, что полученный им план может оказаться менее эффективным и, как следствие, увеличится время выполнения запроса. Управлять его включением более тонко помогает параметр geqo_threshold. |
| geqo_threshold | 12 | Задаёт минимальное число элементов во FROM, при котором для планирования запроса будет привлечён генетический оптимизатор. Для более простых запросов лучше использовать обычный планировщик, для запросов со множеством таблиц обычное планирование может занять слишком много времени, в этом случае выгоднее потерять на качестве плана, но выполнить планирование быстро. |
| enable_* | on | Все параметры, начинающиеся на "enable_", например, "enable_mergejoin", "enable_nestloop" рекомендуется не трогать и оставить по умолчанию. Если отключение какого-либо параметра помогло ускорить один запрос, то другие запросы могут наоборот начать работать медленнее. Параметр "enable_mergejoin" платформа 1С сама явно отключает при выполнении каждого запроса. |
| jit | off | Увеличивает время планирования сложных запросов 1С, поэтому отключаем |
| enable_index_path_selectivity | on | Включение данной настройки позволяет с большей вероятностью задействовать покрывающий все условия индекс. При включении изменяется алгоритм выбора лучшего индексного пути для отношений используемых запросом с учетом лучшей селективности для перебираемых индексных путей, но только в случае:
Такие индексные пути будут сравниваться по их селективности - индексный путь с лучшей селективностью будет иметь приоритет. |
| enable_convert_exists_as_lateral_join | on | Включение данной настройки позволяет оптимизировать некоторые запросы, использующие механизм РЛС. При включении планировщик будет выбирать более оптимальный план выполнения за счет того, что вместо подзапроса, будет использоваться соединение таблиц. |
| enable_join_pushdown | on | Включение данной настройки позволяет оптимизировать запросы обращения к виртуальным таблицам 1С за счет проталкивания условий соединения с виртуальной таблицей внутрь подзапроса. |
| enable_group_by_reordering | on | Включение данной настройки позволяет оптимизировать запросы, использующие агрегаты, за счет переупорядочивания полей сортировки и адаптивного применения GroupAggregate/HashAggregate |
| enable_or_expansion | on | Включение данной настройки позволяет оптимизировать запросы с дизъюнкцией подзапросов (конструкции вида "WHERE EXISTS(...) OR EXISTS(...)"): планировщик автоматически преобразует их в объединение независимых запросов через UNION ALL с устранением дубликатов, что дает возможность применить индексный доступ к каждому условию отдельно вместо полного сканирования таблицы. |
| enable_filter_predicates_reordering | on | Включение данной настройки позволяет оптимизировать запросы с различными типами сканирования за счет оптимизации порядка применения фильтров: наиболее селективные условия проверяются первыми. |
| enable_parallel_insert | on | Включение данной настройки позволяет использовать параллелизм в запросах, результат которых помещается во временную таблицу |
Автовакуум (Autovacuum)
| Имя параметра | Рекомендуемое значение | Описание |
| autovacuum | on | Включение автовакуума. Его выключение приведет к росту размера базы и падению производительности |
| log_autovacuum_min_duration | 5s | Записываем в лог СУБД все запросы autovacuum длительнее указанного значения для разбора инцидентов |
| autovacuum_max_workers | CPU/2 | Количество процессов автовакуума. Общее правило - чем больше запросов на запись выполняется в системе (такие системы называются OLTP), тем больше значение нужно установить, но не более половины доступных ядер. |
| autovacuum_naptime | 20s | Время сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать «чиститься», что приведет к росту размера и снижению производительности работы. Малая величина приведет к бесполезной нагрузке. |
| autovacuum_vacuum_scale_factor | 0.01 | Указывается доля размера таблицы, добавляемая к autovacuum_vacuum_threshold, при принятии решения о запуске autovacuum_vacuum. |
| autovacuum_vacuum_threshold | 1000 | Задаёт минимальное число изменённых или удалённых кортежей, при котором будет выполняться autovacuum_vacuum для отдельно взятой таблицы. Формула для срабатывания autovacuum_vacuum: число ненужных (измененных или удаленных) кортежей > (autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * число строк в таблице) |
| autovacuum_analyze_scale_factor | 0.005 | Указывается доля размера таблицы, добавляемая к autovacuum_analyze_threshold, при принятии решения о запуске autovacuum_analyze. Если в базе имеется большое количество таблиц, в которых идет интенсивное изменение данных, то это значение можно еще уменьшить. |
| autovacuum_analyze_threshold | 50 | Задаёт минимальное число изменённых кортежей в таблице, при котором будет выполняться autovacuum_analyze для отдельно взятой таблицы. Данное значение можно оставить по умолчанию равным 50. Формула для срабатывания autovacuum_analyze: число измененных кортежей > (autovacuum_analyze_threshold + autovacuum_analyze_scale_factor * число строк в таблице) |
| autovacuum_vacuum_insert_scale_factor | 0.01 | Процент вставленных кортежей в таблице для срабатывания autovacuum_vacuum. |
| autovacuum_vacuum_insert_threshold | 1000 | Количество вставленных кортежей в таблице для срабатывания autovacuum_vacuum. Формула для срабатывания autovacuum_analyze: число вставленных кортежей > (autovacuum_vacuum_insert_threshold + autovacuum_vacuum_insert_scale_factor * число строк в таблице) |
| autovacuum_vacuum_cost_limit | autovacuum_max_workers*100 | Tantor Postgres считает суммарную стоимость работы каждого воркера. Порог стоимости при которой все процессы autovacuum встанут в паузу на autovacuum_vacuum_cost_delay |
| autovacuum_vacuum_cost_delay | 2ms | После того как все процессы автовакуума достигнут порог стоимости указанный в autovacuum_vacuum_cost_limit, то они остановятся, подождут указанное в текущем параметре время и продолжат работать дальше. Это делается для того, чтобы снизить нагрузку на систему (диски, cpu). |
Индивидуальные опции (Customized Options)
auto_explain
Данный модуль вместе с платформой Tantor позволит в удобном виде получать планы проблемных запросов. Подробнее об этой возможности можно узнать по следующим ссылкам:
- Раздел Advanced analytics в платформе Tantor - https://tantorlabs.ru/page39398236.html
- Лекции по работе с планами запросов модуля - https://www.youtube.com/playlist?list=PLt0vzWoDuwcRWoeVHeJuDhnXRnjiMMTOF
Включать данный модуль мы рекомендуем только в том случае, если у вас развита практика оптимизации проблемных запросов и на это выделяются ресурсы разработчиков или экспертов 1С. В ином случае собирать эти статистические данные смысла нет и включать данный модуль не нужно. Также этот модуль может оказывать влияние на производительность.
| Имя параметра | Рекомендуемое значение | Описание |
| auto_explain.log_analyze | on | Включает использование данного модуля. |
| auto_explain.log_buffers | true | Определяет, будет ли при протоколировании плана выполнения выводиться статистика об использовании буферов; он равносилен указанию BUFFERS команды EXPLAIN |
| auto_explain.log_verbose | true | Определяет, будут ли при протоколировании плана выполнения выводиться подробные сведения; он равнозначен указанию VERBOSE команды EXPLAIN |
| auto_explain.log_min_duration | 5000ms | Время выполнения оператора, в миллисекундах, при превышении которого план оператора будет протоколироваться. По сути при установке данного параметра в 5000 мс будут протоколироваться все запросы, время выполнения которых более или равно данному значению. |
| auto_explain.log_nested_statements | on | При включении параметра протоколированию могут подлежать и вложенные операторы (операторы, выполняемые внутри функции). Когда он отключён, протоколируются планы запросов только верхнего уровня. |
| auto_explain.sample_rate | 0.2 | Задает процент запросов, которые будут отслеживаться, в данном случае каждый 5й запрос. |
Более подробно включение модуля Advanced analytics рассмотрено здесь.
online_analyze
Данный модуль активно применялся в 1С до версии платформы 8.3.13 для моментального обновления статистики при создании временной таблицы. Начиная с 8.3.13 платформа сама выполняет команду ANALYZE для созданной временной таблицы (если она содержит хотя бы одну запись) и смысла включать этот плагин с table_type = temporary нет.
Но если включите, ты после создания временной таблицы команда ANALYZE выполняться будет все равно 1 раз (проверено по логам postgres), поэтому на производительность в худшую сторону это не повлияет.
| Имя параметра | Рекомендуемое значение | Описание |
| online_analyze.enable | off | Включает использование данного модуля. Если версия платформы более 8.3.13, то off, иначе on. При off указанные ниже настройки смысла не имеют |
| online_analyze.table_type | temporary | Включает синхронное автообновление статистики на указанных таблицах. Возможные значения: Типы таблиц, для которых выполняется немедленный анализ: all (все), persistent (постоянные), temporary (временные), none (никакие). |
| online_analyze.verbose | off | Отключает подробные сообщения расширения online_analyze (выполнение инструкции ANALYZE без опции VERBOSE) |
| online_analyze.threshold | 50 | Минимальное число изменений строк, после которого может начаться немедленный ANALYZE |
| online_analyze.scale_factor | 0.1 | Процент от размера таблицы, при котором начинается немедленный ANALYZE |
| online_analyze.min_interval | 10000 | Минимальный интервал времени между вызовами ANALYZE для отдельной таблицы (в миллисекундах). |
| online_analyze.local_tracking | on | Включает в online_analyze отслеживание временных таблиц в рамках обслуживающего процесса. Когда эта переменная отключена (off), online_analyze использует для временных таблиц системную статистику по умолчанию. |
pg_stat_statements
Данный модуль позволяет собирать статистику для анализа выполняющихся в системе запросов. Например, самые часто выполняющиеся запросы или запросы, которые утилизируют больше всего CPU. Но специфика 1С состоит в активном использовании временных таблиц, из-за чего агрегировать одинаковые запросы с разными именами временных таблиц становится проблематично. В Tantor Postgres данная проблема решена.
| Имя параметра | Рекомендуемое значение | Описание |
| pg_stat_statements.mask_temp_tables | on | Включает маскирование имен временных таблиц. Имена всех временных таблиц будут заменены на константу "TEMPTABLE" |
| pg_stat_statements.sample_rate | 0.75 | Указывает какая часть запросов попадает в выборку. Для многопроцессорных высоконагруженных систем сбор информации по всем запросам может негативно сказаться на пропускной способности. Наши нагрузочные тесты показали, что деградация начинается при значении выше 0.75, поэтому мы рекомендуем использовать значения в интервале 0.50 - 0.75 |
pg_query_id
Данный модуль позволяет влиять на формирование queryid для запросов, что в свою очередь позволяет корректно агрегировать большее количество похожих запросов, например, в pg_stat_statements.
| Имя параметра | Рекомендуемое значение | Описание |
| pg_query_id.enabled | on | Включает использование данного модуля |
| pg_query_id.ignore_temp_tables | on | Включение данного параметра позволяет игнорировать имя временной таблицы. В совокупности с включенной настрокой pg_stat_statements.mask_temp_tables это позволяет корректно агрегировать все запросы с временными таблицами. |
| pg_query_id.ignore_constant_arrays | on | Включение данного параметра позволяет игнорировать массивы, такие как "ARRAY[]", "VALUES ()", "IN ()" |
| pg_query_id.utility_constant_query_id | on | Включение данного параметра заменяет имена таблиц при выполнении DML и некоторых DDL-команд, например, "COPY FROM", "DROP TABLE", "CREATE INDEX" и т.д. |
pg_stat_advisor
Данный модуль позволяет автоматически создавать расширенную статистику для таблиц базы данных. Основанием для создания статистики является расхождение в оценке предварительного и фактического количества строк узла плана запроса.
| Имя параметра | Рекомендуемое значение | Описание |
| pg_stat_advisor.suggest_statistics_threshold | 0.1 | Отношение предварительного количества строк к фактическому. Если это отношение меньше этого параметра, то будет создаваться расширенная статистика. Например, значение 0.1 будет создавать расширенную статистику в том случае, если предварительное количество строк будет меньше фактического в 10 раз. |
| pg_stat_advisor.enable_analyze | on | Включение данного параметра вызывает команду ANALYZE сразу после создания расширенной статистики. |
| pg_stat_advisor.min_duration | '1000ms' | Время выполнения запроса, в миллисекундах, при превышении которого узлы плана запроса будут анализироваться на предмет расхождения оценки строк |
Прочие
| Имя параметра | Рекомендуемое значение | Описание |
|---|---|---|
| plantuner.fix_empty_table | on | Отключает излишнюю пессимистичность Tantor Postgres в отношении только что созданных таблиц |
Совместимость с версиями и платформами (Version and Platform Compatibility)
| Имя параметра | Рекомендуемое значение | Описание |
|---|---|---|
| escape_string_warning | off | Не выдавать предупреждение об использовании символа \ для экранирования. |
| standard_conforming_strings | off | Разрешает использовать символ \ для экранирования |
Значения по умолчанию для клиентского подключения (Client Connection Defaults)
| Имя параметра | Рекомендуемое значение | Описание |
|---|---|---|
| row_security | off | Отключение контроля на уровне записей, т.к. у 1С свой собственный механизм РЛС. |
| shared_preload_libraries | online_analyze, plantuner, pg_stat_statements, pg_store_plans, auto_explain | Список дополнительных библиотек, загружаемых при запуске postgres. |
| default_toast_compression | lz4 | Эта переменная устанавливает метод сжатия по умолчанию TOAST для значений сжимаемых столбцов. Поддерживаемые методы сжатия - pglz и lz4. По умолчанию используется pglz, но lz4 лучше сжимает данные, позволяя экономить место, и использует меньше ресурсов процессора. |
Управление блокировками (Lock Management)
| Имя параметра | Рекомендуемое значение | Описание |
|---|---|---|
| max_locks_per_transaction | 512 | Максимальное число блокировок индексов/таблиц в одной транзакции. Для высоконагруженных систем с большими конфигурациями с большим числом таблиц рекомендуется устанавливать значение больше, например, 1000. |
Регламентное обслуживание
Настройка регламентных операций
Для оптимизации операций autovacuum на рабочих серверах рекомендуется настроить следующие регламентные операции СУБД:
- /opt/tantor/db/15/bin/vacuumdb -h 127.0.0.1 -p 5432 -U postgres -a -Z -j 4 - Analyze only - всех баз в 4 потока (количество потоков можно увеличить до 8 в зависимости от количества ядер и скорости дисковой подсистемы) - Ежедневно
- /opt/tantor/db/15/bin/vacuumdb -h 127.0.0.1 -p 5432 -U postgres -a -z -F -j 2 - Vacuum + Analyze + Freeze всех баз в 2 потока (количество потоков можно увеличить до 4-8 в зависимости от количества ядер и скорости дисковой подсистемы) - Еженедельно
Эти операции можно настроить интерактивно с помощью платформы Tantor следующим образом:
1. Переходим в модуль "Задачи" и добавляем новую Задачу

2. Заполняем задачу по примеру как на изображении:
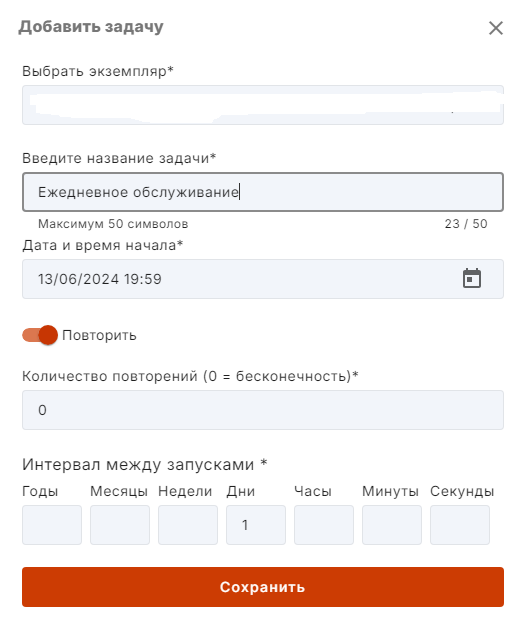
В разделе "Интервал между запусками" ставим 1 в поле "Дни" - это означает, что задача будет выполняться каждый день.
3. После создания задачи кликаем на нее и провалимся в раздел "Действия", в котором добавляем новое действие - выбираем "Системная команда"
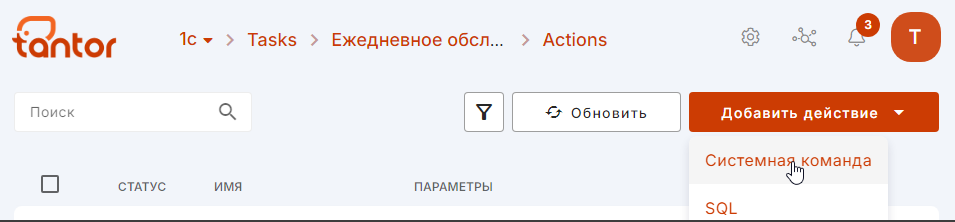
4. Заполняем команду по примеру как на изображении:
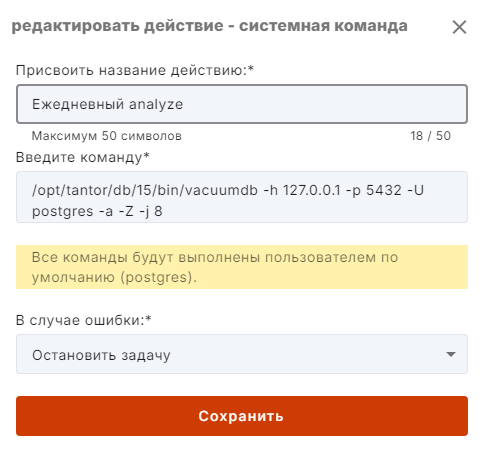
5. Нажимаем "Сохранить" - на этом ежедневное регламентное обслуживание настроено.
6. По аналогии создаем задачу и команду для еженедельного регламентного обслуживания
Самостоятельное обслуживание таблиц
В случае удаления значимого объёма данных из базы (более 20%) имеет смысл выполнить vacuum full таблицы, из которой были удалены данные. Vacuum full требует монопольного доступа и блокировки базы 1С.
Выполнить данное обслуживание можно из платформы Tantor из раздела Maintenance:
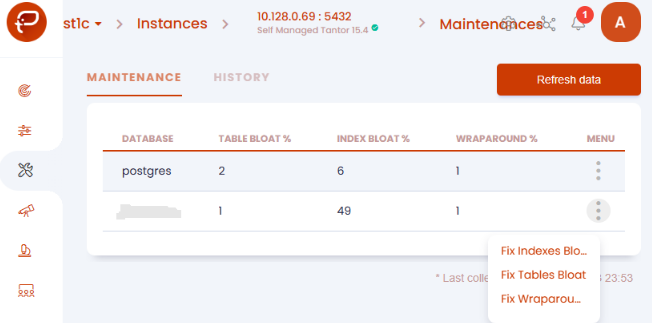
Для того, чтобы выполнять обслуживание без монопольного доступа к таблицам можно использовать следующие утилиты, которые идут в сборке СУБД Tantor SE 1C:
Настройки ОС
Сетевой адаптер
Для максимальной производительности рекомендуется сетевой трафик между СП и СУБД вывести на отдельный адаптер, чтобы он не ходил по общей сети.
То, что есть задержки по сети, можно определить следующим способом: выполнить простейший запрос время выполнения которого, например, 0.01 сек. При выполнении собирать технологический журнал (событие DBPOSTGRS) и трассировку СУБД, затем сравнить время выполнения запросов по данным этих логов. Если время выполнения одного запроса по данным технологического журнала 1С будет на порядок больше чем по данным логов СУБД, то проблема есть. При правильно настроенном сетевом взаимодействии между СП и СУБД разница выполнения будет несколько миллисекунд.
Временные таблицы
Работа с временными таблицами создает дополнительную нагрузку на диск. Подробно это рассмотрено в данной статье.
Поэтому рекомендуем выносить каталог с временными таблицами либо на отдельный диск либо в RAM. Вынос в RAM имеет свои нюансы, но на высоконагруженных системах может быть оправдан.
Вынос в RAM для Astralinux:
Создаем директорию, в котором будут хранится файлы временных таблиц и даем права пользователю postgres:
mkdir /mnt/dbtemp
chmod 700 /mnt/dbtemp
chown postgres:postgres /mnt/dbtempСоздаем табличное пространство:
CREATE TABLESPACE temp LOCATION '/mnt/dbtemp';В результате внутри директории /mnt/dbtemp будет создан каталог вида PG_15_202209061. Внутри него для каждой базы будет создаваться свой каталог с именем равным oid'у базы. Чтобы каталог базы появился необходимо в базе создать временную таблицу.
Узнать oid базы можно следующим скриптом:
SELECT oid from pg_databaseВ RAM можно вынести как целиком каталог PG_15_202209061, так и каталог конкретной базы.
Рассмотрим вынос каталога временных таблиц конкретной базы, в нашем примере для нее был создан каталог 16439. Добавим в файл /etc/fstab следующую строку:
tmpfs /mnt/dbtemp/PG_15_202209061/16439 tmpfs rw,nodev,nosuid,noatime,nodiratime,size=1G 0 0Выделили под него 1 Гб. Монтируем RAM-диск:
mount /mnt/dbtemp/PG_15_202209061/16439 Меняем параметр temp_tablespaces в postgresql.conf:
temp_tablespaces = 'temp'И перечитываем настройки постгреса:
SELECT pg_reload_conf();Каталог pg_stat_tmp
Данная рекомендация актуальна для Tantor Postgres ниже 15й версии. В 15 версии Tantor Postgres архитектура сбора статистики была основательно переработана. Теперь нет процесса для сбора статистики, ее генерируют серверные процессы Tantor Postgres самостоятельно и обмениваются ей в оперативной памяти.
В обязательном порядке необходимо вынести каталог pg_stat_tmp в RAM-диск. Этот каталог очень агрессивно используется Tantor Postgres и при этом при выключении его содержимое копируется в каталог pg_tmp. Размер каталога рассчитывается примерно как work_mem*2 на 1 БД.
Для CentOS и Astralinux:
Для начала создадим директорию:
mkdir /home/data/pg_stat_tmp
chown postgres:postgres /home/data/pg_stat_tmpв файле /etc/fstab добавить строку:
tmpfs /home/data/pg_stat_tmp tmpfs noatime,nodiratime,defaults,size=512Mсохранить файл и далее выполнить:
mount -a
rebootМеняем параметр в postgresql.conf:
stats_temp_directory = '/home/data/pg_stat_tmp'Перезапускаем СУБД:
systemctl restart tantor-se-1c-server-14Transparent Huge Pages
Согласно бенчмаркам THP на 10% ускоряют абстрактное приложение, но на деле всё по другому. В некоторых случаях THP вызывает ничем не мотивированное увеличение потребления CPU в системе, поэтому рекомендуем выключать их.
Для CentOS:
в файле /etc/default/grub в строку GRUB_CMDLINE_LINUX добавить
transparent_hugepage=never
On BIOS-based machines: grub2-mkconfig -o /boot/grub2/grub.cfg
On UEFI-based machines: grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
reboot
Для Astralinux:
Начиная с версии 1.8 THP будут отключены по умолчанию
В файле /etc/default/grub в строку GRUB_CMDLINE_LINUX добавить значение transparent_hugepage=never
GRUB_CMDLINE_LINUX="transparent_hugepage=never"Если в строке указывается несколько параметров, то они разделяются пробелом
После этого выполнить
# update-grub2
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.15.0-70-generic
Found initrd image: /boot/initrd.img-5.15.0-70-generic
Warning: os-prober will be executed to detect other bootable partitions.
Its output will be used to detect bootable binaries on them and create new boot entries.
done
#После перезагрузки убедиться что изменения применены, можно командой :
# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]Параметр AnonHugePages должен быть равен 0
root@ep2-mongolog00:~# cat /proc/meminfo
MemTotal: 4017664 kB
MemFree: 2734024 kB
...
AnonHugePages: 0 kB
...I/O scheduler
Для SSD и NVMe-устройств лучше ставить планировщик none / noop, который уменьшает нагрузку на CPU, а вот для HDD-дисков лучше использовать mq-deadline, который показывает лучшие результаты по итогам синтетических тестов:
Для CentOS:
grubby --update-kernel=ALL –args="elevator=noop"
rebootДля Astralinux 1.7:
в файле /etc/default/grub в строку GRUB_CMDLINE_LINUX добавить значение elevator=noop
GRUB_CMDLINE_LINUX="elevator=noop"после чего выполнить
# update-grub2
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.15.0-70-generic
Found initrd image: /boot/initrd.img-5.15.0-70-generic
Warning: os-prober will be executed to detect other bootable partitions.
Its output will be used to detect bootable binaries on them and create new boot entries.
done
#После перезагрузки убедиться что изменения применены, можно командой :
# cat /sys/block/sda/queue/scheduler
[noop] mq-deadline cfqНастройка sysctl.conf
Рекомендации для получения максимальной производительности Tantor Postgres, значения параметров необходимо пересчитать исходя из параметров вашего сервера СУБД:
| Имя параметра и рекомендуемое значение | Описание |
|---|---|
| vm.swappiness=1 | Параметр ядра, который может влиять на производительность базы данных. Этот параметр используется для управления поведением подкачки (swappiness) (подкачки страниц в память и из нее) в Linux. Значение варьируется от 0 до 100. Он определяет, сколько памяти будет выгружено или выгружено. Ноль означает отключение обмена, а 100 означает агрессивный обмен. Вы можете получить хорошую производительность, установив более низкие значения. Установка значения 0 в более новых ядрах может привести к тому, что OOM Killer (процесс очистки памяти в Linux) убьет процесс. Таким образом, можно безопасно установить значение 1, если хотите минимизировать подкачку. Значение по умолчанию в Linux — 60. Более высокое значение заставляет MMU (блок управления памятью) использовать больше пространства подкачки, чем ОЗУ, тогда как более низкое значение сохраняет больше данных/кода в памяти. Меньшее значение — хорошая ставка на улучшение производительности в Tantor Postgres. |
| vm.nr_hugepages=65536 | Значение этого параметра обязательно нужно вычислчть для каждого отдельного сервера СУБД! Tantor Postgres поддерживает большие страницы только в Linux. По умолчанию Linux использует 4 КБ страниц памяти, поэтому в случаях, когда операций с памятью слишком много, необходимо устанавливать страницы большего размера. Наблюдается прирост производительности при использовании больших страниц размером 2 МБ и до 1 ГБ. Размер большой страницы может быть установлен во время загрузки. Скрипт определения количества больших страниц
Вывод скрипта выглядит следующим образом:
|
vm.overcommit_ratio=50 vm.overcommit_memory=2 | Приложения получают память и освобождают ее, когда она больше не нужна. Но в некоторых случаях приложение получает слишком много памяти и не освобождает ее. Это может вызвать OOM killer. Вот возможные значения параметра vm.overcommit_memory с описанием для каждого:
Ссылка: https://www.kernel.org/doc/Documentation/vm/overcommit-accounting vm.overcommit_ratio — процент оперативной памяти, доступной для чрезмерной загрузки. Значение 50% в системе с 2 ГБ ОЗУ может выделять до 3 ГБ ОЗУ. Значение 2 для vm.overcommit_memory обеспечивает лучшую производительность для Tantor Postgres. Это значение максимизирует использование оперативной памяти серверным процессом без какого-либо значительного риска быть убитым процессом OOM killer. Приложение сможет перезагружаться, но только в пределах перерасхода, что снижает риск того, что OOM killer убьет процесс. Следовательно, значение 2 дает лучшую производительность, чем значение по умолчанию 0. Тем не менее, надежность может быть улучшена за счет того, что память за пределами допустимого диапазона не будет перегружена. Это исключает риск того, что процесс будет убит OOM-killer. |
vm.dirty_bytes = 268435456 # 256 MB | vm.dirty_*ratio опасны! Поэтому только *_bytes и при том весьма агрессивные. Данный параметр необходимо рассчитать исходя из количества ОЗУ на вашем сервере СУБД |
vm.dirty_background_bytes = 1073741824 # 1024 MB | Объём системной памяти, который можно заполнить dirty pages до того, как фоновые процессы pdflush/flush/kdmflush запишут их на диск |
vm.min_free_kbytes = 1048576 # 1 Гб | Данный параметр говорит ядру стараться держать часть памяти свободной, а чтобы удовлетворить это требование, ему приходится запускать дефрагментацию раньше. |
kernel.sched_migration_cost_ns = 5000000 | Время, в течение которого шедуллер считает процесс достаточно горячим, чтобы не мигрировать его на другой CPU |
vm.zone_reclaim_mode = 0 | Ядро не пытается выделить память путем ее высвобождения, а выделяет там где есть в том числе и на другой NUMA-ноде. |
kernel.numa_balancing=0 | Отключить работу NUMA для CPU, т.к. Tantor Postgres ее не поддерживает. |
fs.file-max = 1000000 | Количество открытых файлов (1М) |
fs.inotify.max_user_watches = 100000 | Сколько файлов может отслеживать один пользователь |
vm.admin_reserve_kbytes=100000 | Размер памяти, который будет гарантированно не занят в системе, чтобы у нас могли работать SSH и пр. |
Загрузка из DT
Процесс загрузки DT состоит из следующих этапов:
- Создаём таблицы согласно метаданным
- Наполняем таблицы данными
- Создаём индексы согласно метаданным
Для ускорения пунктов 2 и 3 можно сделать следующие настройки:
- Отключить автовакуум - autovacuum=off
- Сделать режим комиттов более пакетным - commit_delay=100000
- Если используете многопоточную загрузку из DT, то параметр commit_siblings поставьте равным количеству этих потоков, чтобы commit_delay работал.
- Увеличить работу сессии в RAM - work_mem=2GB
- Увеличить объем памяти для создания индексов - maintenance_work_mem=4GB
- При использовании Tantor Postgres для ускорения создания индексов выставить параметр max_parallel_maintenance_workers = 50% ядер сервера. Но если используете многопоточную загрузку из DT, то ставьте не более 20% ядер, чтобы создание нескольких больших индексов на разных таблицах не заняло все ресурсы процессора.
После окончания загрузки необходимо обязательно провести Analyze only базы 1С и вернуть настройки к «боевому» режиму.
Возможности платформы 1С для ускорения процесса миграции между СУБД:
Начиная с платформы 8.3.19 загрузка из DT может выполняться многопоточно, количество потоков ограничивается количеством ядер на сервере приложений. В документации это описано здесь. Следует учитывать, что одна таблица может грузиться только в одном потоке.
Начиная с платформы 8.3.23 миграция между различными СУБД может выполняться без выгрузки информационной базы в DT. В документации это описано здесь и здесь.
Выполнение запросов из 1С
При выполнении каждого запроса платформа 1С явно устанавливает следующие параметры:
SET client_min_messages=error;
SET lc_messages to 'en_US.UTF-8';
SET enable_mergejoin=off;
SET escape_string_warning=off;
SET standard_conforming_strings=off;
SET cpu_operator_cost=0.001;
SET client_encoding='UTF8';
SET lock_timeout=20000;Параметры enable_mergejoin и cpu_operator_cost могут сильно влиять на выбор плана запроса, поэтому если выполнить EXPLAIN ANALYZE без этих параметров, то можно получить совсем другой план, не тот который выбирается планировщиком при выполнении из 1С.
Параметр lock_timeout берется из параметра информационной базы 1С "Время ожидания блокировки данных (в секундах)".
История версий
ver. 1.0 from 13.12.23
Создана инструкция
ver 1.1 from 03.02.24
default_statistics_target: 500 → 100
ver 1.2 from 11.05.24
jit: on → off
ver 1.3 from 21.06.24
Дополнен раздел "Регламентное обслуживание": настройка регламентного обслуживания с помощью модуля "Задачи" платформы Tantor.
ver 1.4 from 22.07.24
from_collapse_limit: 10 → 20
join_collapse_limit: 10 → 20
default_toast_compression: pglz → lz4
ver 1.5 from 18.12.24
Добавлена новая настройка enable_index_path_selectivity
ver 1.6 from 12.02.25
auto_explain.sample_rate: 1 → 0.2
ver 1.7 from 02.06.25
Добавлены новые настройки:
- enable_convert_exists_as_lateral_join
- enable_join_pushdown
- enable_group_by_reordering
- enable_delayed_temp_file
- enable_temp_memory_catalog
Добавлены новые пункты в раздел "Индивидуальные опции":
- pg_stat_statements
- pg_query_id
- pg_stat_advisor
ver 1.8 from 22.10.25
Добавлены новые настройки:
- default_statistics_target_temp_tables
- enable_filter_predicates_reordering
- enable_or_expansion
- enable_pgstat_for_temp_rel
- enable_parallel_insert