Download PDF
Download page Хранилища на базе файловой технологии хранения.
Хранилища на базе файловой технологии хранения
Особенности файловой технологии хранения
Файловая технология хранения позволяет хранить образы дисков в виде файла. В качестве системы хранения данных (СХД) может выступать локальное хранилище сервера (например, специально выделенное блочное устройство) или внешнее хранилище. В ПК СВ поддерживаются внешние хранилища, построенные на таких технологиях, как NAS и SAN:
- NAS (Network Attached Storage – сетевое хранилище данных) обеспечивает доступ к данным на уровне файлов;
- SAN (Storage Area Network – сеть хранения данных) обеспечивает доступ к данным на уровне блочных устройств.
Файловая технология хранения подразумевает, что подключенные системы хранения данных размечены с использованием одной из файловых систем.
Рекомендуется иметь несколько хранилищ, построенных на базе файловой технологии хранения и с применением различных методов передачи данных, для:
- распределения операций ввода-вывода между серверами хранения данных;
- обеспечения непрерывности обслуживания.
Образы сохраняются в соответствующий каталог хранилища (по умолчанию /var/lib/one/datastores/<идентификатор_хранилища>). Для каждой ВМ создается каталог с названием по идентификационному номеру ВМ в соответствующем системном хранилище. В данных каталогах содержатся диски ВМ и дополнительные файлы, например, файлы контрольных точек или файлы снимков.
Создание и настройка системы хранения данных
При настройке внешнего хранилища необходимо руководствоваться инструкциями производителя оборудования.
Пример подключения внешнего хранилища SAN по протоколу iSCSI
В данном примере описан процесс настройки сервера, предоставляющего блочные данные по протоколу iSCSI (программная СХД). Сетевые блочные устройства (iSCSI-target), предоставляемые этим сервером, будут подключены в качестве локальных блочных устройств на другом сервере (iSCSI-initiator).
В данном примере представлены минимально необходимые настройки.
Особенности использования SAN в ПК СВ
SAN обеспечивает предоставление блочных устройств посредством сетевых протоколов, таких как Fibre Channel или iSCSI. Для доступа к определенному сетевому блочному устройству используется специализированный адрес этого устройства – LUN (Logical Unit Number – номер логического устройства).
Для организации хранения в ПК СВ требуется выделение как минимум 2 LUN (один – для хранилища образов, второй – для системного хранилища). Эти LUN должны быть презентованы каждому серверу - фронтальным машинам и узлам виртуализации.
Дополнительная информация
Пример использования сетевых блочных устройств при создании хранилищ для тестового стенда.Настройки сервера, предоставляющего блочные устройства (iSCSI-target)
Вывести перечень блочных устройств:
lsblkПример вывода после выполнения команды:NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 3,9G 0 rom sda 252:0 0 12G 0 disk ├─sda1 252:1 0 11G 0 part / ├─sda2 252:2 0 1K 0 part └─sda5 252:5 0 975M 0 part [SWAP] sdb 252:16 0 24G 0 disk sdc 252:32 0 24G 0 diskCODEгде:
sda– диск для размещения файлов ОС;sdbиsdc– диски для эмуляции сетевых блочных устройств.
Установить консоль управления Linux-IO Target (пакет
targetcli-fb):sudo apt install targetcli-fbВойти в консоль управления Linux-IO Target командой:
sudo targetcliВ консоли управления вывести текущую конфигурацию командой:
lsПример вывода после выполнения команды:/> ls o- / ..................................................................................................... [...] o- backstores ......................................................................................... [...] | o- block ............................................................................ [Storage Objects: 0] | o- fileio ........................................................................... [Storage Objects: 0] | o- pscsi ............................................................................ [Storage Objects: 0] | o- ramdisk .......................................................................... [Storage Objects: 0] o- iscsi ...................................................................................... [Targets: 0] o- lo.......................................................................................... [Targets: 0] o- vhost ...................................................................................... [Targets: 0]CODEСоздать (зарегистрировать) блочное устройство в разделе
/backstores/blockкомандой:/backstores/block create <наименование_устройства> /dev/<блочное_устройство>
В наименовании устройства могут использоваться любые печатные символы, за исключением символов кириллицы .

Пример
Регистрация блочного устройства
/dev/sdb, при этом ему будет присвоено условное именованиеstorage01:/backstores/block create storage01 /dev/sdbПример вывода после выполнения команды:
Created block storage object storage01 using /dev/sdb.CODE- Аналогичным образом добавить необходимое количество блочных устройств.
Проверить результат командой
ls. Пример вывода после выполнения команды:/> ls o- / ................................................................................................. [...] o- backstores ........................................................................................ [...] | o- block ............................................................................ [Storage Objects: 1] | | o- storage01 ............................................... [/dev/sdb (24.0GiB) write-thru deactivated] | o- fileio ........................................................................... [Storage Objects: 0] | o- pscsi ............................................................................ [Storage Objects: 0] | o- ramdisk .......................................................................... [Storage Objects: 0] o- iscsi ...................................................................................... [Targets: 0] o- loopback ................................................................................... [Targets: 0] o- vhost ...................................................................................... [Targets: 0]CODEСоздать цель (iSCSI-target) в разделе
/iscsiкомандой:/iscsi createПример вывода после выполнения команды:Created target iqn.2003-01.org.linux-iscsi.storage.x8664:sn.4668ea6d5709. Created TPG 1. Global pref auto_add_default_portal=true Created default portal listening on all IPs (0.0.0.0), port 3260.CODE
Для каждого блочного устройства можно назначить несколько целей (iSCSI-target) – чтобы разграничить доступ для разных групп серверов-инициаторов (iSCSI-initiator).
Проверить результат командой
ls. Пример вывода после выполнения команды:/> ls o- / ..................................................................................................... [...] o- backstores ......................................................................................... [...] | o- block ............................................................................ [Storage Objects: 1] | | o- storage01 ............................................... [/dev/sdb (24.0GiB) write-thru deactivated] | o- fileio ........................................................................... [Storage Objects: 0] | o- pscsi ............................................................................ [Storage Objects: 0] | o- ramdisk .......................................................................... [Storage Objects: 0] o- iscsi ...................................................................................... [Targets: 1] | o- iqn.2003-01.org.linux-iscsi.storage.x8664:sn.4668ea6d5709 ................................... [TPGs: 1] | o- tpg1 ......................................................................... [no-gen-acls, no-auth] | o- acls .................................................................................... [ACLs: 0] | o- luns .................................................................................... [LUNs: 0] | o- portals .............................................................................. [Portals: 1] | o- 0.0.0.0:3260 ............................................................................... [OK] o- loopback ................................................................................... [Targets: 0] o- vhost ...................................................................................... [Targets: 0]CODEСоздать LUN на основе блочного устройства, зарегистрированного в разделе
/backstores/block(см. шаг 5) командой:/iscsi/<идентификатор_цели>/tpg1/luns/ create /backstores/block/<наименование_устройства>
Пример
/iscsi/iqn.2003-01.org.linux-iscsi.storage.x8664:sn.4668ea6d5709/tpg1/luns/ create /backstores/block/storage01Пример вывода после выполнения команды:
Created LUN 0.CODEПроверить результат командой
ls. Пример вывода после выполнения команды:/> ls o- / ..................................................................................................... [...] o- backstores ......................................................................................... [...] | o- block ............................................................................ [Storage Objects: 1] | | o- storage01 ............................................... [/dev/sdb (24.0GiB) write-thru deactivated] | o- fileio ........................................................................... [Storage Objects: 0] | o- pscsi ............................................................................ [Storage Objects: 0] | o- ramdisk .......................................................................... [Storage Objects: 0] o- iscsi ...................................................................................... [Targets: 1] | o- iqn.2003-01.org.linux-iscsi.storage.x8664:sn.4668ea6d5709 ................................... [TPGs: 1] | o- tpg1 ......................................................................... [no-gen-acls, no-auth] | o- acls .................................................................................... [ACLs: 0] | o- luns .................................................................................... [LUNs: 0] | | o- lun0 ............................................ [block/storage01 (/dev/sdb) (default_tg_pt_gp)] | o- portals .............................................................................. [Portals: 1] | o- 0.0.0.0:3260 ............................................................................... [OK] o- loopback ................................................................................... [Targets: 0] o- vhost ...................................................................................... [Targets: 0]CODEВыполнить настройку контроля доступа к цели (iSCSI-target):
если контроль доступа не требуется, то его можно отключить командами:
cd /iscsi/<идентификатор_цели>/tpg1
set attribute generate_node_acls=1
set attribute demo_mode_write_protect=0
для предоставления доступа определенному серверу-инициатору (iSCSI-initiator) к цели (iSCSI-target) необходимо в список доступа (ACL) добавить идентификатор инициатора, который хранится в файле
/etc/iscsi/initiatorname.iscsiна сервере-инициаторе (см. шаг 3 настройки iSCSI-initiator). Для этого следует выполнить команды:cd /iscsi/<идентификатор_цели>/tpg1/acls
create <идентификатор_инициатора>
Пример
cd /iscsi/iqn.2003-01.org.linux-iscsi.storage.x8664:sn.4668ea6d5709/tpg1/acls
create iqn.1993-08.org.debian:01:c1a92326f6b8Пример вывода после успешного выполнения команды
create:Created Node ACL for iqn.1993-08.org.debian:01:c1a92326f6b8 Created mapped LUN 0.CODE
- Повторить шаги 8 – 12 для добавления необходимого количества LUN.
Выполнить сохранение настроек:
/ saveconfigПример вывода после выполнения команды:Last 10 configs saved in /etc/rtslib-fb-target/backup. Configuration saved to /etc/rtslib-fb-target/saveconfig.jsonCODEВыйти из консоли управления:
exit
В консоли управления Linux-IO Target версии 2.1.48-2 введена система бэкапов конфигурации. В связи с этим, после перезагрузки сервера сохраненная конфигурация не загружается автоматически. На текущий момент после перезагрузки сервера конфигурацию необходимо восстанавливать командой:
Пример вывода после выполнения команды:
Configuration restored from /etc/rtslib-fb-target/saveconfig.jsonДля того чтобы автоматизировать восстановление конфигурации, необходимо выполнить следующие действия:
Создать службу
target, сформировав unit-файл, например с помощью тестового редактора nano, для этого выполнить команду:sudo nano /lib/systemd/system/target.serviceВ открывшемся текстовом редакторе добавить следующие строки:[Unit] Description=Restore LIO kernel target configuration Requires=sys-kernel-config.mount After=sys-kernel-config.mount network.target local-fs.target [Service] Type=oneshot RemainAfterExit=yes ExecStart=/usr/bin/targetctl restore ExecStop=/usr/bin/targetctl clear SyslogIdentifier=target [Install] WantedBy=multi-user.targetCODEПосле этого сохранить unit-файл и закрыть текстовый редактор.
Перезагрузить список служб командой:
sudo systemctl daemon-reloadДобавить службу
targetв автозагрузку командой:sudo systemctl enable targetПример вывода после выполнения команды:Created symlink /etc/systemd/system/multi-user.target.wants/target.service → /lib/systemd/system/target.service.CODEДля проверки следует перезагрузить сервер и вывести информацию о состоянии службы
target:sudo systemctl status targetПример вывода после выполнения команды:
● target.service - Restore LIO kernel target configuration Loaded: loaded (/lib/systemd/system/target.service; enabled; vendor preset: enabled) Active: active (exited) since Mon 2023-03-20 16:28:26 MSK; 9min ago Process: 577 ExecStart=/usr/bin/targetctl restore (code=exited, status=0/SUCCESS) Main PID: 577 (code=exited, status=0/SUCCESS)CODE
Настройки сервера (iSCSI-initiator), которому презентованы сетевые блочные устройства
Установить пакет
open-iscsiкомандой:sudo apt install open-iscsiНастроить автоматическое подключение
LUNпри перезагрузке сервера. Для этого в конфигурационном файле/etc/iscsi/iscsid.confдля параметраnode.startupустановить значениеautomatic:node.startup = automaticCODEЗапустить службу клиента (
iSCSI-initiator) командой:sudo systemctl start iscsiПосле первого запуска сервиса будет сгенерирован уникальный идентификатор инициатора, который можно просмотреть в файле
/etc/iscsi/initiatorname.iscsi.
Пример
InitiatorName=iqn.1993-08.org.debian:01:c1a92326f6b8CODEЕсли для цели (iSCSI-target) настроен контроль доступа, то уникальный идентификатор инициатора необходимо добавить в список доступа (ACL) цели (
iSCSI-target) – см. шаг 12 настройки iSCSI-target.Выполнить сканирование для поиска целей (
iSCSI-target):sudo iscsiadm -m discovery -t st -p <IP-адрес_цели>где <IP-адрес_цели> – IP-адрес узла, предоставляющего доступ к блочному устройству.
Пример вывода после успешного выполнения команды:192.168.55.41:3260,1 iqn.2003-01.org.linux-iscsi.iscsi-target.x8664:sn.76c72e49ddc1 192.168.55.41:3260,1 iqn.2003-01.org.linux-iscsi.iscsi-target.x8664:sn.85eebbd1f098CODEПодключить найденную цель (iSCSI-target):
sudo iscsiadm -m node -T <идентификатор_цели> -p <IP-адрес_цели> -l
Пример
sudo iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.iscsi-target.x8664:sn.76c72e49ddc1 -p 192.168.55.41 -lКроме того, можно автоматически подключить все найденные цели (iSCSI-target):
sudo iscsiadm -m node -lПример вывода после успешного выполнения команды:Logging in to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi-target.x8664:sn.76c72e49ddc1, portal: 192.168.55.41,3260] (multiple) Logging in to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi-target.x8664:sn.85eebbd1f098, portal: 192.168.55.41,3260] (multiple) Login to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi-target.x8664:sn.76c72e49ddc1, portal: 192.168.55.41,3260] successful. Login to [iface: default, target: iqn.2003-01.org.linux-iscsi.iscsi-target.x8664:sn.85eebbd1f098, portal: 192.168.55.41,3260] successful.CODE
В случае, если при подключении целей возникли ошибки, необходимо выполнить одну из следующих команд:
- sudo iscsiadm -m session --rescan
- sudo iscsiadm -m session -P3
Если после выполнения команды, указанной выше, ошибка не была устранена, необходимо перезапустить службу
iscsiкомандой:sudo systemctl restart iscsiили перезагрузить сервер командой:sudo rebootДля проверки выполнить команду:
lsblkПример вывода после выполнения команды:NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 24G 0 disk sdb 8:16 0 24G 0 disk sr0 11:0 1 1024M 0 rom vda 252:0 0 64G 0 disk ├─vda1 252:1 0 63G 0 part / ├─vda2 252:2 0 1K 0 part └─vda5 252:5 0 975M 0 part [SWAP]CODEгде в качестве локальных блочных устройств
sdaиsdbвыступают сетевые блочные устройства.
Настройки ПК СВ для использования хранилища
Перед использованием подключенные блочные устройства (локальные или внешние) необходимо разметить (отформатировать) с использованием одной из файловых систем. Ниже представлены примеры форматирования блочных устройств sda и sdb, подключенных ранее, с использованием файловых систем OCFS2 и NFS.
Ограничения, связанные с функционированием файловой системы NFS
Сетевая файловая система NFS не поддерживает использование меток безопасности. Если планируется использование файловой системы NFS при построении облачного хранилища, функционирующего в мандатном контексте, то для ВМ следует установить уровень целостности, назначаемый по умолчанию, равным 0.
Если в ПК СВ, функционирующем в дискреционном режиме, планируется использовать файловую систему NFS, то на каждом узле виртуализации следует установить уровень целостности, назначаемый по умолчанию для ВМ, равным 0. Для этого необходимо выполнить действия, описанные ниже.
Остановить службу
libvirtdкомандой:sudo systemctl stop libvirtd.serviceВ конфигурационном файле
/etc/libvirt/libvirtd.conf, установить значение параметраilev_vmравное 0.ilev_vm = 0CODEЗапустить службу
libvirtdкомандой:sudo systemctl start libvirtd.service
Пример использования кластерной файловой системы OCFS2
Особенности использования OCFS2 в ПК СВ
В ПК СВ кластерная файловая система OCFS2 используется для того, чтобы обеспечить доступ фронтальной машины и узла виртуализации к одним и тем же сетевым блочным устройствам. При этом все сервера (фронтальные машины и узлы виртуализации) объединяются в один кластер OCFS2 и выступают в роли узлов этого кластера.
Кластерная файловая система OCFS2, реализованная в ПК СВ, обеспечивает поддержку меток безопасности, но имеет ряд зафиксированных критических проблем функционирования.
В связи с этим использование OCFS2 на объектах эксплуатации не рекомендуется.
Дополнительная информация
Пример создания хранилищ для тестового стенда с использованием кластерной файловой системы OCFS2.Создание кластера OCFS2
По умолчанию после инициализации кластера установлен режим local heartbeat.
На каждом узле кластера установить средства управления кластерной файловой системой OCFS2 командой:
sudo apt install ocfs2-tools- Настроить старт службы OCFS2 после настройки сетевых соединений при запуске ОС:
- в файле
/lib/systemd/system/o2cb.serviceсделать запись:After=network-online.target remote-fs-pre.targetCODE - перезапустить службу:
sudo systemctl restart o2cb.serviceCODE
- в файле
- На одном из узлов кластера выполнить настройку кластера OCFS2:
создать кластер командой:
sudo o2cb add-cluster <имя_кластера>
Пример
sudo o2cb add-cluster ocfs2clusterВ результате выполнения команды будет создан файл конфигурации
/etc/ocfs2/cluster.conf, если он отсутствует.последовательно добавить описание каждого узла кластера командой:
sudo o2cb add-node <имя_кластера> <сетевое_имя_узла> --ip <IP-адрес_узла>
Пример для кластера из трех узлов
sudo o2cb add-node ocfs2cluster node1 --ip 192.168.55.11
sudo o2cb add-node ocfs2cluster node2 --ip 192.168.55.12
sudo o2cb add-node ocfs2cluster node3 --ip 192.168.55.13

Сетевые имена узлов кластера должны быть точно такими, какими они указаны в файле
/etc/hostnameэтих серверов.
Просмотреть итоговый файл конфигурации, например, с помощью команды:
cat /etc/ocfs2/cluster.confПример вывода после выполнения команды:cluster: name = ocfs2cluster heartbeat_mode = local node_count = 3 node: name = node1 cluster = ocfs2cluster number = 0 ip_address = 192.168.55.11 ip_port = 7777 node: name = node2 cluster = ocfs2cluster number = 1 ip_address = 192.168.55.12 ip_port = 7777 node: name = node3 cluster = ocfs2cluster number = 2 ip_address = 192.168.55.13 ip_port = 7777CODE- На других узлах кластера выполнить следующие действия:
скопировать файл конфигурации
/etc/ocfs2/cluster.confс узла кластера, на котором была выполнена настройка конфигурации (шаги 2 – 4), в локальный каталог/etc/ocfs2/:sudo scp <локальный_администратор>@<IP-адрес_узла>:/etc/ocfs2/cluster.conf /etc/ocfs2/где:- <IP-адрес_узла> – IP-адрес узла кластера, на котором была выполнена настройка конфигурации;
- <локальный_администратор> – имя локального администратора узла кластера, на котором была выполнена настройка конфигурации.
В ходе выполнения команды необходимо:- при появлении запроса пароля для команды
sudo– ввести пароль локального администратора узла кластера, на котором выполняется команда; - при появлении вопроса об установке соединения – ответить "yes" ("Да");
- ввести пароль локального администратора узла кластера, с которого копируется файл конфигурации.
просмотреть полученный файл конфигурации, например, с помощью команды:
cat /etc/ocfs2/cluster.confСодержание файла конфигурации должно отражать выполненные ранее настройки.
- После того, как файл конфигурации будет скопирован на другие узлы, на каждом узле кластера выполнить следующие действия:
запустить мастер настройки кластера OCFS2 командой:
sudo dpkg-reconfigure ocfs2-toolsВ запустившемся мастере:- разрешить запускать кластер OCFS2 (O2CB) во время загрузки (нажать на кнопку [Да]);
- задать имя кластера (для кластера в приведенных выше примерах: "ocfs2cluster") и нажать на кнопку [Ok];
- для остальных параметров выбрать значения, установленные по умолчанию;
перезапустить службу
o2cbкомандой:sudo systemctl restart o2cbудостовериться в успешном запуске службы
o2cb. Для этого просмотреть в журнале регистрации события, относящиеся к службе:sudo journalctl -u o2cbПример вывода после выполнения команды:мар 23 09:40:58 oneserver.brest.local systemd[1]: Starting Load o2cb Modules... мар 23 09:40:58 oneserver.brest.local o2cb[20018]: checking debugfs... мар 23 09:40:58 oneserver.brest.local o2cb[20018]: Loading stack plugin "o2cb": OK мар 23 09:40:58 oneserver.brest.local o2cb[20018]: Loading filesystem "ocfs2_dlmfs": OK мар 23 09:40:59 oneserver.brest.local o2cb[20018]: Creating directory '/dlm': OK мар 23 09:40:59 oneserver.brest.local o2cb[20018]: Mounting ocfs2_dlmfs filesystem at /dlm: OK мар 23 09:40:59 oneserver.brest.local o2cb[20018]: Setting cluster stack "o2cb": OK мар 23 09:40:59 oneserver.brest.local o2cb[20018]: Registering O2CB cluster "ocfs2cluster": OK мар 23 09:40:59 oneserver.brest.local o2cb[20018]: Setting O2CB cluster timeouts : OK мар 23 09:40:59 oneserver.brest.local o2hbmonitor[20070]: Starting мар 23 09:40:59 oneserver.brest.local systemd[1]: Started Load o2cb Modules.CODE
- Перейти к разметке блочных устройств.
Настройка режима global heartbeat
Для контроля исправности узла кластера используется специальный heartbeat-файл, в который узел кластера периодически записывает контрольную информацию. По умолчанию после инициализации кластера OCFS2 установлен режим local heartbeat. В этом режиме heartbeat-файл создается на каждом примонтированом сетевом блочном устройстве. При этом для каждого heartbeat-файла на узле кластера запускается процесс мониторинга, который обеспечивает выполнение операций чтения heartbeat-файла и записи в этот файл. При большом количестве примонтированных сетевых блочных устройств создается значительная нагрузка на вычислительные мощности узла кластера.
Режим global heartbeat подразумевает, что heartbeat-файл создается на специально выделенном сетевом блочном устройстве. Такой режим рекомендуется применять в случае, если количество сетевых блочных устройств, к которым организован совместный доступ, больше 50.
Перед настройкой режима global heartbeat необходимо выполнить шаги 1-6 по созданию кластера OCFS2.
Выделенное сетевое блочное устройство (далее по тексту – heartbeat-диск), на котором будет создан общий ("глобальный") heartbeat-файл, должно быть предварительно размечено (отформатировано) с использованием кластерной файловой системы OCFS2. Для этого на одном из узлов кластера необходимо выполнить команду:
где:
- аргумент
--global-heartbeatозначает, что в кластере настроен режимglobalheartbeat. Данная информация записывается в блок метаданных о кластере и должна присутствовать на всех отформатированных блочных устройствах, которые планируется монтировать на узлах кластера; - аргумент
-Fвыключает проверку блочного устройства перед форматированием. Указанное блочное устройство не должно быть примонтировано ни на одном из узлов кластера. Однако, так как в аргументе команды указано, что в кластере настроен режимglobalheartbeat, такая проверка не может быть выполнена (на момент выполнения команды режимglobalheartbeatв кластере еще не настроен).
Пример
Пример вывода после выполнения команды:
Device Stack Cluster F UUID Label
/dev/sda o2cb ocfs2cluster G AA36F57B447E483D810DEC89BDEAB1C9 heartbeat-diskгде символ "G" в поле F (Flag) указывает на то, что блочное устройство настроено на работу в режиме global heartbeat.
Для настройки режима global heartbeat на всех узлах кластера необходимо выполнить действия, описанные ниже.
Допускается выполнить настройку на одном из узлов кластера. А затем, скопировать файл конфигурации /etc/ocfs2/cluster.conf на остальные узлы.
На всех узлах кластера файлы конфигурации /etc/ocfs2/cluster.conf должны быть идентичны.
Задать режим в конфигурации кластера командой:
sudo o2cb heartbeat-mode <имя_кластера> global
Пример
sudo o2cb heartbeat-mode ocfs2cluster globalЗаписать информацию о heartbeat-диске в файл конфигурации:
Необходимо создать не менее трех
global heartbeatустройств.Таким образом, для работы с ПК СВ должно быть не менее пяти LUN:
- три LUN для
global heartbeat; - два LUN для хранилища образов и системного хранилища.
Размер LUN для каждого
global heartbeatдолжен быть не менее 3 Гб.sudo o2cb add-heartbeat <имя_кластера> <блочное_устройство>где в качестве параметра <блочное_устройство> можно указать UUID подключенного блочного устройства.
Пример
Подключение в качестве heartbeat-устройства отдельного дискового устройства
/dev/sda (UUID="AA36F57B447E483D810DEC89BDEAB1C9"):sudo o2cb add-heartbeat ocfs2cluster AA36F57B447E483D810DEC89BDEAB1C9
Пример
Ниже приведено содержание файла конфигурации после настройки режима
globalheartbeat.node: name = node1 cluster = ocfs2cluster number = 0 ip_address = 192.168.55.11 ip_port = 7777 node: name = node2 cluster = ocfs2cluster number = 1 ip_address = 192.168.55.12 ip_port = 7777 node: name = node3 cluster = ocfs2cluster number = 2 ip_address = 192.168.55.13 ip_port = 7777 cluster: name = ocfs2cluster heartbeat_mode = global node_count = 3 heartbeat: cluster = ocfs2cluster region = AA36F57B447E483D810DEC89BDEAB1C9CODE- три LUN для
Перезапустить службу
o2cbкомандой:sudo systemctl restart o2cb
Если на узлах кластера были примонтированы сетевые блочные устройства, то после включения режима global heartbeat и перезапуска службы o2cb, они будут автоматически отмонтированы.
Для их последующего монтирования необходимо обновить метаинформацию о кластере, которая была записана на этих блочных устройствах при форматировании.
Для того, чтобы обновить метаинформацию о кластере, которая записана на блочном устройстве, необходимо на одном из узлов кластера выполнить команду:
Changing the clusterstack from default to <метаинформация_о_кластере>. Continue?необходимо ввести "y" ("Да") и нажать клавишу [Enter].
Пример вывода после успешного выполнения команды:
Updated successfully.Разметка блочных устройств
Для того чтобы разметить (отформатировать) подключенное сетевое блочное устройство с использованием кластерной файловой системы OCFS2, на любом из узлов кластера необходимо выполнить команду:
"-T" запускает автоматическую тонкую настройку параметров файловой системы. Параметр "vmstore" указывает, что тонкую настройку необходимо производить для обеспечения максимальной производительности при размещении на блочном устройстве файлов образов виртуальных машин.Метаинформация о кластере (аргументы команды --cluster-stack=o2cb --cluster-name=<имя_кластера> и, при необходимости, --global-heartbeat) будет записана автоматически, при условии, что на узле кластера запущена служба o2cb.
Пример
Пример вывода после выполнения команды:
Device Stack Cluster F UUID Label
/dev/sda o2cb ocfs2cluster G AA36F57B447E483D810DEC89BDEAB1C9 heartbeat-disk
/dev/sdb o2cb ocfs2cluster G EF8246A7E12842168B496FC123B469B2 Если сетевое блочное устройство необходимо повторно форматировать, то его предварительно необходимо отмонтировать на всех узлах кластера.
Для того чтобы просмотреть перечень сетевых блочных устройств с кластерной файловой системой OCFS2, примонтированных на узлах кластера, на любом из узлов кластера необходимо выполнить команду:
Пример вывода после выполнения команды:
Device Stack Cluster F Nodes
/dev/sda o2cb ocfs2cluster G Not mounted
/dev/sdb o2cb ocfs2cluster G node2, node3где:
- диск
sdaне примонтирован ни на одном из узлов кластера; - диск
sdbпримонтирован на узлах кластера:node2иnode3.
Пример использования файловой системы NFS
В представленном примере описан процесс настройки сервера NAS, предоставляющего общий доступ к каталогам, в которые смонтированы блочные устройства. Чтобы обеспечить общий доступ к каталогам, на сервере NAS будет настроена служба сервера NFS, а на фронтальной машине и узлах виртуализации – служба клиента NFS.
Дополнительная информация
Сетевая файловая система NFSДля того чтобы блочные устройства автоматически монтировались в заданные каталоги, на сервере NAS необходимо выполнить действия, описанные ниже.
Вывести перечень блочных устройств:
lsblkПример вывода после выполнения команды:NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 3,9G 0 rom sda 252:0 0 12G 0 disk ├─sda1 252:1 0 11G 0 part / ├─sda2 252:2 0 1K 0 part └─sda5 252:5 0 975M 0 part [SWAP] sdb 252:16 0 24G 0 disk sdc 252:32 0 24G 0 diskCODEгде:
sda– диск для размещения файлов ОС;sdbиsdc– диски для монтирования в каталоги с общим доступом.
Создать файловую систему
ext4на блочном устройствеsdb:sudo mkfs.ext4 /dev/sdbПример вывода после успешного выполнения команды:Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: doneCODE- Аналогичным образом создать файловую систему
ext4на блочном устройствеsdc. Создать каталоги, в которые будут смонтированы блочные устройства, например,
/mnt/nfs-systemи/mnt/nfs-images. Для этого последовательно выполнить команды:sudo mkdir /mnt/nfs-system
sudo mkdir /mnt/nfs-images
На каталоги назначить владельцем пользователя с UID равным 9869 (
oneadmin). А в качестве группы-владельца – группу с GID равным 9869 (oneadmin). Для этого последовательно выполнить команды:sudo chown 9869:9869 /mnt/nfs-system
sudo chown 9869:9869 /mnt/nfs-images
Определить идентификаторы (UUID) блочных устройств командой:
sudo blkidПример вывода после выполнения команды:/dev/sda1: UUID="b5fd411a-4c96-491b-bfc0-b4e9e2670e9c" TYPE="ext4" PARTUUID="50741579-01" /dev/sda5: UUID="31daa40d-8e07-44cc-b851-d985f2121bb7" TYPE="swap" PARTUUID="50741579-05" /dev/sdb: UUID="0bb98072-95ad-4042-bd33-7adf62102445" TYPE="ext4" /dev/sdc: UUID="093051cb-e9c2-4932-99a1-16cab2da8e1c" TYPE="ext4"CODEНастроить автоматическое монтирование блочных устройств в созданные ранее каталоги. Для этого в файл
/etc/fstabдобавить следующие строки:UUID=0bb98072-95ad-4042-bd33-7adf62102445 /mnt/nfs-system ext4 _netdev,errors=remount-ro 0 1 UUID=093051cb-e9c2-4932-99a1-16cab2da8e1c /mnt/nfs-images ext4 _netdev,errors=remount-ro 0 1CODEВыполнить монтирование командой:
sudo mount -aРезультатом выполнения команды должен быть пустой вывод без ошибок.
Для того чтобы установить и настроить службу сервера NFS, на сервере NAS необходимо выполнить действия, описанные ниже.
Установить службу сервера NFS:
sudo apt install nfs-kernel-serverВ конфигурационном файле
/etc/exportsуказать порядок доступа к каталогам. Для этого добавить строки вида:<полный_путь_каталога> <IP-адрес_клиента>(rw,async,no_subtree_check,no_root_squash)CODEгде
<IP-адрес_клиента>– IP-адрес фронтальной машины или узла виртуализации. Кроме того, может быть использовано сетевое имя сервера, или, для указания группы серверов, можно использовать адрес сети или подстановочные знаки (подробнее см. справкуman exports).
Пример
Настройка доступа для фронтальной машины с сетевым именем
frontи узлов виртуализации, сетевое имя которых начинается с последовательности символов "node" (далее следует один любой символ):/mnt/nfs-system front(rw,async,no_subtree_check,no_root_squash) /mnt/nfs-system node?(rw,async,no_subtree_check,no_root_squash) /mnt/nfs-images front(rw,async,no_subtree_check,no_root_squash) /mnt/nfs-images node?(rw,async,no_subtree_check,no_root_squash)CODEОбновить правила доступа к каталогам командой:
sudo exportfs -ra
Для того чтобы установить и настроить службу клиента NFS, на фронтальной машине и каждом узле виртуализации необходимо выполнить действия, описанные ниже.
Установить службу клиента NFS:
sudo apt install nfs-commonПросмотреть перечень доступных сетевых ресурсов:
sudo showmount -e <IP-адрес_сервера_NAS>Пример вывода после успешного выполнения команды:Export list for 192.168.1.10: /mnt/nfs-images node?,front /mnt/nfs-system node?,frontCODEНа всех узлах виртуализации создать точки монтирования.
На объекте эксплуатации в качестве точек монтирования выступают каталоги хранилищ ПК СВ (см. Пример монтирования сетевых ресурсов с NFS).
Настроить автоматическое монтирование сетевых ресурсов в точки монтирования. Для этого в файл
/etc/fstabдобавить строки вида:<IP-адрес_сервера_NFS>:<сетевой_ресурс> <точка_монтирования> nfs _netdev,timeo=14,intr 0 0CODE
Пример
192.168.1.10:/mnt/nfs-images /var/lib/one/datastores/101 nfs _netdev,timeo=14,intr 0 0 192.168.1.10:/mnt/nfs-system /var/lib/one/datastores/100 nfs _netdev,timeo=14,intr 0 0CODEВыполнить монтирование командой:
sudo mount -aРезультатом выполнения команды должен быть пустой вывод без ошибок.
Особенности использования методов передачи данных
Драйверы Shared и Qcow2
При использовании драйвера shared (метода совместной передачи – shared transfer driver) образы экспортируются в соответствующий каталог системного хранилища на узле виртуализации. При этом на всех узлах виртуализации должна быть установлена и настроена общая распределенная (или кластерная) файловая система.
Драйвер qcow2 является разновидностью метода совместной передачи и ориентирован на работу с образами дисков формата qcow2. Образы создаются и передаются с помощью инструмента командной строки qemu-img с использованием исходного образа в качестве опорного файла. Стандартные параметры инструмента командной строки qemu-img можно скорректировать, указав необходимые значения в конфигурационном файле /etc/one/tmrc (переменная QCOW2_OPTIONS).
Схема функционирования представлена на рисунке:

При развертывании ВМ в каталоге системного хранилища (на рисунке выше – каталог "100") создается рабочий каталог ВМ с наименованием, соответствующем идентификатору этой ВМ (на рисунке выше – каталог "7"). Из каталога хранилища образов (на рисунке выше – каталог "101") в рабочий каталог ВМ копируется файл непостоянного образа, указанный в шаблоне ВМ (на рисунке выше – файл "disk.1") и/или формируется символическая ссылка на файл постоянного образа (на рисунке выше – файл "disk.0"). Цифра после префикса "disk." соответствует номеру диска, указанному в шаблоне.
При создании снимка состояния работающей ВМ в рабочем каталоге записывается файл состояния этой ВМ с наименованием вида "snap-<номер>.xml" (где <номер> – порядковый номер снимка, начиная с цифры "0").
При использовании драйвера qcow2 во время создания снимка состояния работающей ВМ также формируется снимок состояния диска этой ВМ. В файл снимка состояния диска записываются изменения в данных, содержащихся на диске (дельта). В качестве наименования файлов снимков состояния диска выступает порядковый номер снимка, начиная с цифры "0". При этом файлы снимков состояния диска размещаются в следующих каталогах:
для непостоянных образов –
/var/lib/one/datastores/<идентификатор_системного_хранилища>/<идентификатор_ВМ>/disk.<идентификатор_диска>.snap/;
Для примера, представленного на рисунке выше –
/var/lib/one/datastores/100/7/disk.1.snap/Файл
disk.1будет являться символической ссылкой на файл актуального снимка состояния диска.для постоянных образов –
/var/lib/one/datastores/<идентификатор_хранилища_образов>/<идентификатор_образа>.snap/;
Для примера, представленного на рисунке выше –
/var/lib/one/datastores/101/6f7f699d.snap/Файл
disk.0будет являться символической ссылкой на файл актуального снимка состояния диска.Кроме того, в рабочем каталоге ВМ будет создана символическая ссылка с наименованием
disk.0.snap, которая указывает на каталог со снимками состояний диска (/var/lib/one/datastores/100/6f7f699d.snap/).
При использовании драйвера qcow2 можно отдельно создать снимок состояния диска как работающей, так и выключенной ВМ. Файлы снимков состояния диска будут размещены в каталогах, описанных выше.
При использовании драйвера shared создание снимка состояния диска работающей ВМ не поддерживается. В качестве снимка состояния диска выключенной ВМ создается полная копия файла диска ВМ. Файлы снимков состояния диска размещаются в каталогах, описанных выше.
Драйвер SSH
Метод передачи ssh использует локальную файловую систему узлов виртуализации для размещения образов виртуальных машин. Таким образом все файловые операции выполняются локально, но образы всегда необходимо копировать на узлы виртуализации. Данный драйвер не допускает использование динамических перемещений между узлами виртуализации.
Схема функционирования представлена на рисунке:
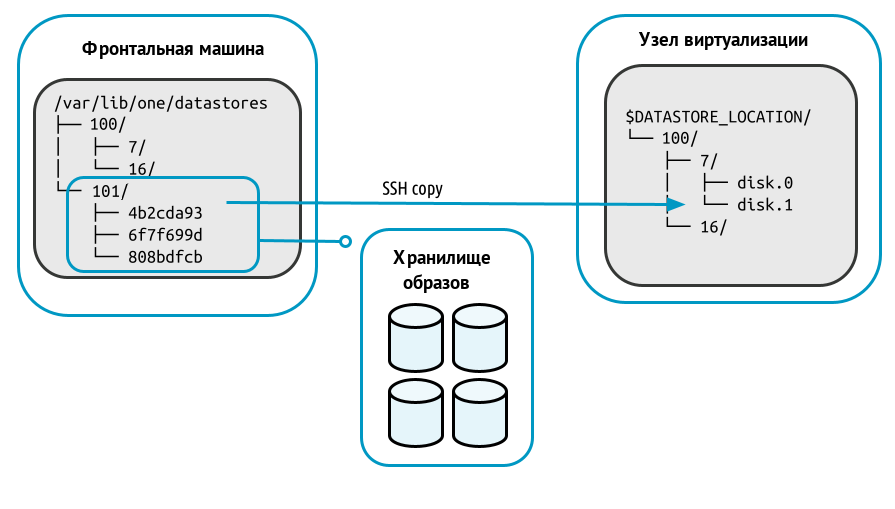
При развертывании ВМ в каталоге системного хранилища на узле виртуализации (на рисунке выше – каталог "100") создается рабочий каталог ВМ с наименованием, соответствующем идентификатору этой ВМ (на рисунке выше – каталог "7"). Из каталога хранилища образов (на рисунке выше – каталог "101") в рабочий каталог ВМ копируется файл исходного образа, указанного в шаблоне ВМ. Копии исходных образов имеют наименование вида "disk.<номер>". (где <номер> – цифра, соответствующая номеру диска в шаблоне).
Необходимо убедиться в том, что все серверы, включая фронтальную машину, могут осуществлять ssh-передачу на любой другой сервер, включая самих себя. В противном случае перемещения не будут выполняться.
При создании снимка состояния работающей ВМ в рабочем каталоге этой ВМ создается файл состояния этой ВМ с наименованием вида "snap-<номер>.xml" (где <номер> – порядковый номер снимка, начиная с цифры "0").
Для выключенной ВМ можно зафиксировать состояние диска этой ВМ (сделать снимок). При этом файлы снимков состояния диска являются полной копией файла диска ВМ и размещаются в каталоге /var/lib/one/datastores/<идентификатор_системного_хранилища>/<идентификатор_ВМ>/disk.<номер>.snap/.
Для файла образа диска disk.1 (см. рис. выше) – /var/lib/one/datastores/100/7/disk.1.snap/
В качестве наименования файлов снимков состояния диска выступает порядковый номер снимка, начиная с цифры "0".
Если в качестве исходного выступал постоянный образ, то при уничтожении ВМ все файлы снимков состояний диска будут перемещены в хранилище образов в каталог /var/lib/one/datastores/<идентификатор_хранилища_образов>/<идентификатор_образа>.snap/.
Для файла образа диска disk.1 (см. рис. выше) все файлы из /var/lib/one/datastores/100/7/disk.1.snap/ будут перемещены в каталог /var/lib/one/datastores/101/4b2cda93.snap/
Регистрация хранилищ
Параметры хранилищ
В общем случае для регистрации облачного хранилища необходимо указать значения следующих параметров:
для системного хранилища:
Параметр Значение NAME<Имя хранилища>TYPESYSTEM_DSTM_MAD<драйвер>(метод передачи данных между хранилищем образов и системным хранилищем).Может принимать одно из следующих значений:
shared,qcow2илиsshдля хранилища образов:
Параметр Значение NAME<Имя хранилища>TYPEIMAGE_DSDS_MAD<базовая технология хранения>TM_MAD<драйвер>(метод передачи данных между хранилищем образов и системным хранилищем).Может принимать одно из следующих значений:
shared,qcow2илиsshSAFE_DIRSПеречень каталогов, разделенных символом пробела, из которых разрешен импорт образа в хранилище.
По умолчанию имеет значение "
/var/tmp"
Необходимо использовать одинаковый метод передачи данных (параметр TM_MAD) для системного хранилища и для хранилища образов.
Регистрация хранилищ в интерфейсе командной строки
Пример
Регистрация системного хранилища, в котором используется драйвер qcow2:
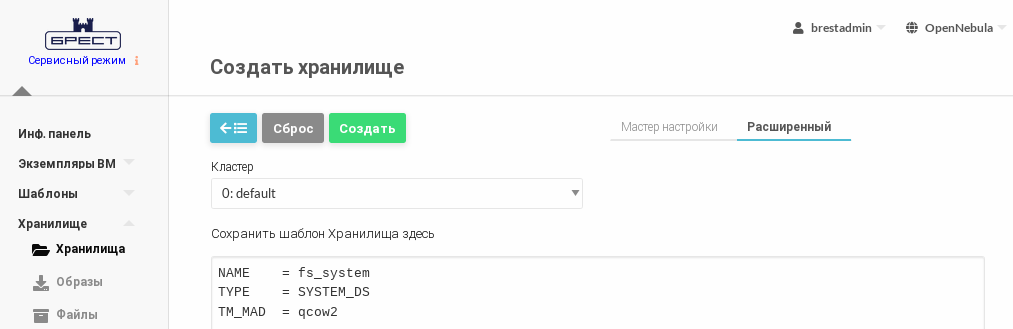
Создать файл
systemds.txtследующего содержания:NAME = fs_system TYPE = SYSTEM_DS TM_MAD = qcow2CODEВыполнить команду:
onedatastore create systemds.txtПосле выполнения команды будет выведен идентификатор созданного хранилища, например:ID: 100CODE
Пример
Регистрация хранилища образов, в котором используется драйвер qcow2:
Создать файл
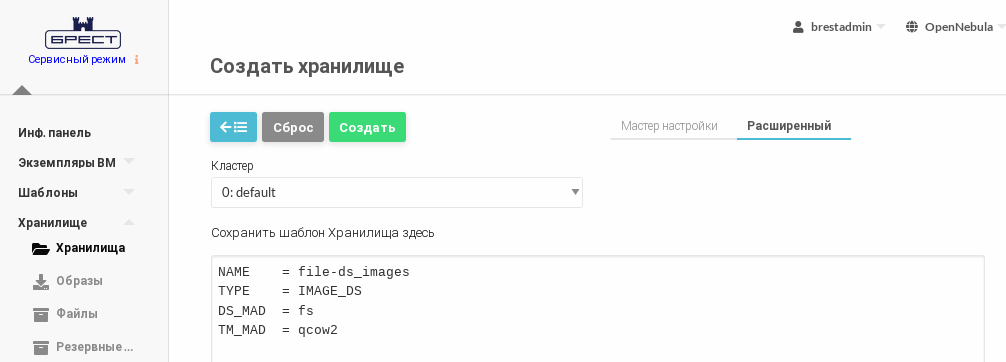
imageds.txtследующего содержания:NAME = fs_images TYPE = IMAGE_DS DS_MAD = fs TM_MAD = qcow2CODEВыполнить команду:
onedatastore create imageds.txtПосле выполнения команды будет выведен идентификатор созданного хранилища, например:ID: 101CODE
Регистрация хранилищ в веб-интерфейсе
Пример
Регистрация системного хранилища, в котором используется драйвер qcow2.
- В веб-интерфейсе ПК СВ в меню слева выбрать пункт меню Хранилище — Хранилища и на открывшейся странице Хранилища нажать на кнопку [+], а затем в открывшемся меню выбрать пункт Создать.
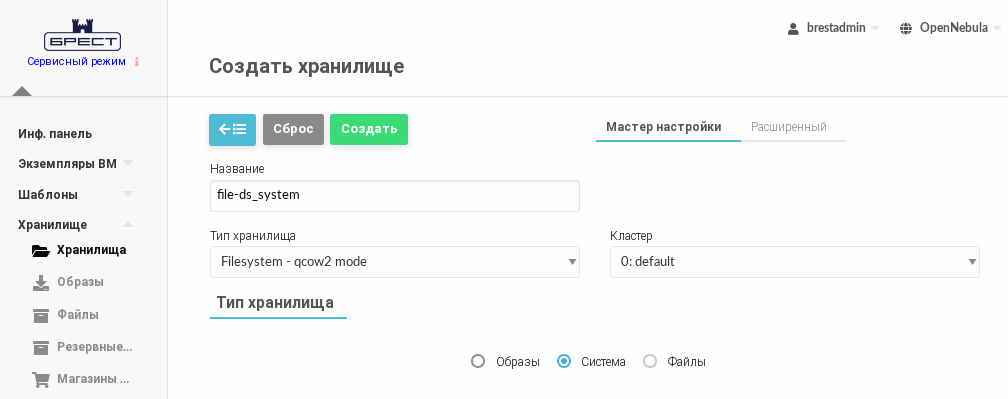
- На открывшейся странице Создать хранилище зарегистрировать хранилище одним из способов:
- во вкладке Мастер настройки:
- в поле Название задать наименование хранилища;
- в выпадающем списке Тип хранилища выбрать значение Filesystem - qcow2 mode;
- установить флаг Система;
- нажать на кнопку [Создать];
- во вкладке Расширенный указать непосредственно значения параметров хранилища.
- во вкладке Мастер настройки:
- Дождаться когда на странице Хранилища для созданного хранилища в поле Статус будет установлено значение ON.
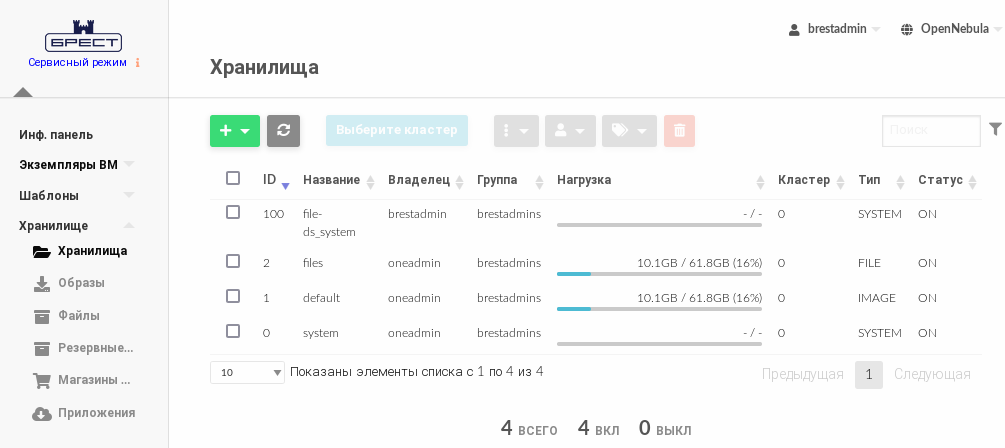
В представленном примере системному хранилищуfile-ds_systemприсвоен идентификатор100.
Пример
Регистрация хранилища образов, в котором используется драйвер qcow2.
- В веб-интерфейсе ПК СВ в меню слева выбрать пункт меню Хранилище — Хранилища и на открывшейся странице Хранилища нажать на кнопку [+], а затем в открывшемся меню выбрать пункт Создать.
- На открывшейся странице Создать хранилище зарегистрировать хранилище одним из способов:
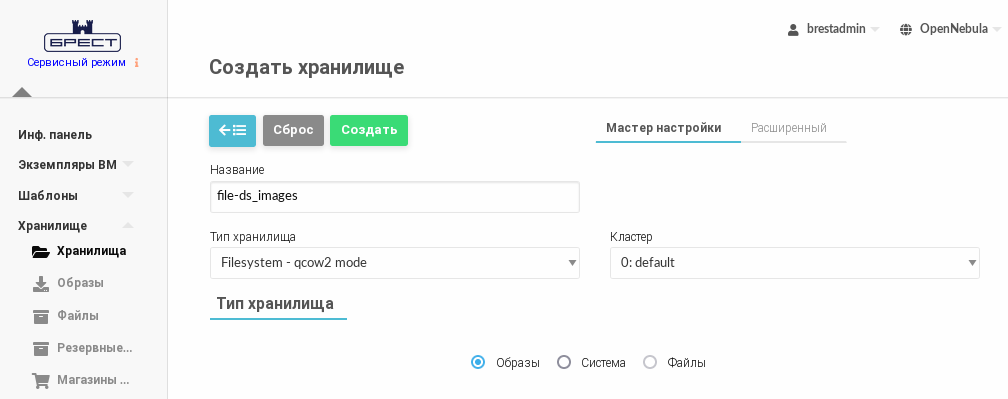
- во вкладке Мастер настройки:
- в поле Название задать наименование хранилища;
- в выпадающем списке Тип хранилища выбрать значение Filesystem - qcow2 mode;
- установить флаг Образы;
- нажать на кнопку [Создать];
- во вкладке Расширенный указать непосредственно значения параметров хранилища.
- во вкладке Мастер настройки:
- Дождаться когда на странице Хранилища для созданного хранилища в поле Статус будет установлено значение ON.
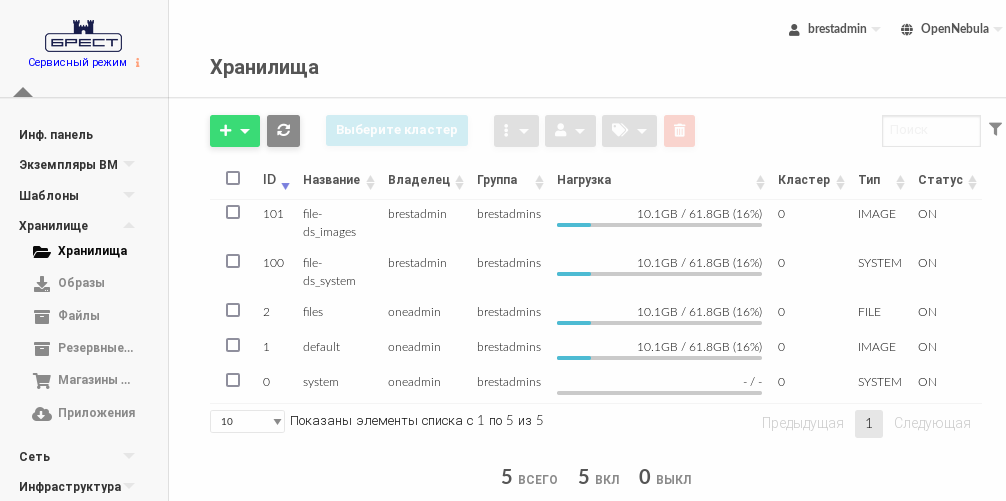
В представленном примере хранилищу образовfile-ds_imagesприсвоен идентификатор101.
Монтирование блочных устройств в каталоги хранилищ
Особенности монтирования блочных устройств в ПК СВ
На узле виртуализации необходимо создать каталоги для созданных ранее хранилищ на базе файловой технология хранения (по умолчанию /var/lib/one/datastores/<идентификатор_хранилища>). Для этого последовательно выполнить команды:
sudo mkdir /var/lib/one/datastores/<идентификатор_системного_хранилища>
sudo mkdir /var/lib/one/datastores/<идентификатор_хранилища_образов>
Пример
sudo mkdir /var/lib/one/datastores/100
sudo mkdir /var/lib/one/datastores/101
На узле виртуализации необходимо смонтировать подготовленную систему хранения данных в каталог хранилища. Если все хранилища одного типа, можно смонтировать весь каталог /var/lib/one/datastores.
На фронтальной машине необходимо смонтировать только хранилище образов.
Кроме того, необходимо убедиться в том, что на смонтированном дисковом ресурсе достаточно места для хранения образов и дисков виртуальных машин, которые находятся в состоянии «остановлена» и «не размещена».
Пример монтирования сетевых блочных устройств с OCFS2
Определить идентификаторы (UUID) сетевых блочных устройств командой:
sudo blkidПример вывода после выполнения команды:/dev/vda1: UUID="b5fd411a-4c96-491b-bfc0-b4e9e2670e9c" TYPE="ext4" PARTUUID="50741579-01" /dev/vda5: UUID="31daa40d-8e07-44cc-b851-d985f2121bb7" TYPE="swap" PARTUUID="50741579-05" /dev/sdb: UUID="3bd71b84-6463-42ec-8aff-106cafdae2e2" TYPE="ocfs2" /dev/sda: UUID="41ff6399-368e-4b81-bae4-bdfa4aedd45a" TYPE="ocfs2"CODEгде в качестве блочных устройств
sdaиsdbвыступают сетевые блочные устройства.В файл
/etc/fstabдобавить следующие строки:UUID=41ff6399-368e-4b81-bae4-bdfa4aedd45a /var/lib/one/datastores/100 ocfs2 _netdev,x-systemd.requires=o2cb.service 0 0 UUID=3bd71b84-6463-42ec-8aff-106cafdae2e2 /var/lib/one/datastores/101 ocfs2 _netdev,x-systemd.requires=o2cb.service 0 0CODEтаким образом на блочном устройстве
sdaбудет размещено системное хранилище, а на блочном устройствеsdb– хранилище образов.Выполнить монтирование командой:
sudo mount -aРезультатом выполнения команды должен быть пустой вывод без ошибок.- Выполнить перезагрузку.
-
После добавления записи об автоматическом монтировании в файле
/etc/fstabи перезагрузки ОС, необходимо назначить на каталог этого хранилища владельцаoneadmin. В противном случае при перезагрузке ОС владелец меняется наrootи использование хранилища будет не доступно.Для того чтобы назначить на каталог хранилища владельца
oneadminнеобходимо выполнить команду:sudo chown oneadmin:oneadmin /var/lib/one/datastores/<идентификатор_хранилища>
Пример
sudo chown oneadmin:oneadmin /var/lib/one/datastores/100
sudo chown oneadmin:oneadmin /var/lib/one/datastores/101
Пример монтирования сетевых ресурсов с NFS
Для каждого сетевого каталога, предоставляемого сетевым хранилищем, предварительно необходимо назначить владельцем пользователя с UID равным 9869 (oneadmin). А в качестве группы-владельца – группу с GID равным 9869 (oneadmin).
Подробнее – см. Пример использования файловой системы NFS.
На фронтальной машине и каждом узле виртуализации необходимо выполнить последовательность действий, описанную ниже.
Установить службу клиента NFS:
sudo apt install nfs-commonПросмотреть перечень доступных сетевых ресурсов:
sudo showmount -e <IP-адрес_сервера_NAS>Пример вывода после успешного выполнения команды:Export list for 192.168.1.10: /mnt/nfs-images node?,front /mnt/nfs-system node?,frontCODEНастроить автоматическое монтирование сетевых ресурсов в точки монтирования. Для этого в файл
/etc/fstabдобавить строки вида:<IP-адрес_сервера_NFS>:<сетевой_ресурс> <точка_монтирования> nfs _netdev,timeo=14,intr 0 0CODEВ качестве точек монтирования необходимо указать каталоги созданных хранилищ.
Пример
192.168.1.10:/mnt/nfs-images /var/lib/one/datastores/101 nfs _netdev,timeo=14,intr 0 0 192.168.1.10:/mnt/nfs-system /var/lib/one/datastores/100 nfs _netdev,timeo=14,intr 0 0CODEВыполнить монтирование командой:
sudo mount -aРезультатом выполнения команды должен быть пустой вывод без ошибок.